 1.35 ALIS
1.35 ALIS  0.00 ALIS
0.00 ALIS 
最近よく考える。
社会のあらゆる階層の人たちが「一つの情報システム」にアクセスし、そこで知識を得、また自らの知識を提供する。
有益な知識の提供には報酬を、利用には費用をそれぞれ享受または賦課する。
知識は正確性が確保されなければならない。
そのための手段として「ブロックチェーン理論」の登場だ。
高度に分散化されたAIビッグデータの輪を、世界の無数のコンピューターで実現する。
以下が私の描く構想だ。
自立型サブスクリプション方式によるAIビッグデータの活用モデル
1、 はじめに
自立型サブスクリプション方式によるAIビッグデータ(以下「AIビッグデータ」と
呼ぶ)は、世界のあらゆる階層の人間、組織の指導者等が対価を支払い自由にアクセス
できる「総合知」としての地位を保持するものである。
「AIビッグデータ」にアクセスすることで、利用者から運営者に支払われる対価は、
運用コストや情報提供者への報酬などの必要経費を差し引いて、その残額がSDGs活動
への資金に充てられることとなる。
結果として、この「AIビッグデータ」運用システムは、SDGs活動(Societ
y5.0活動を含む)において我々が提唱する「持続可能社会の整備確立」に貢献する「持続可能」な「総合知の運用創出モデル兼資金調達システム」としての地位を併せ持つ。
2、モデルの概略
「AIビッグデータ」はおおむね以下のような構成条件を想定している。
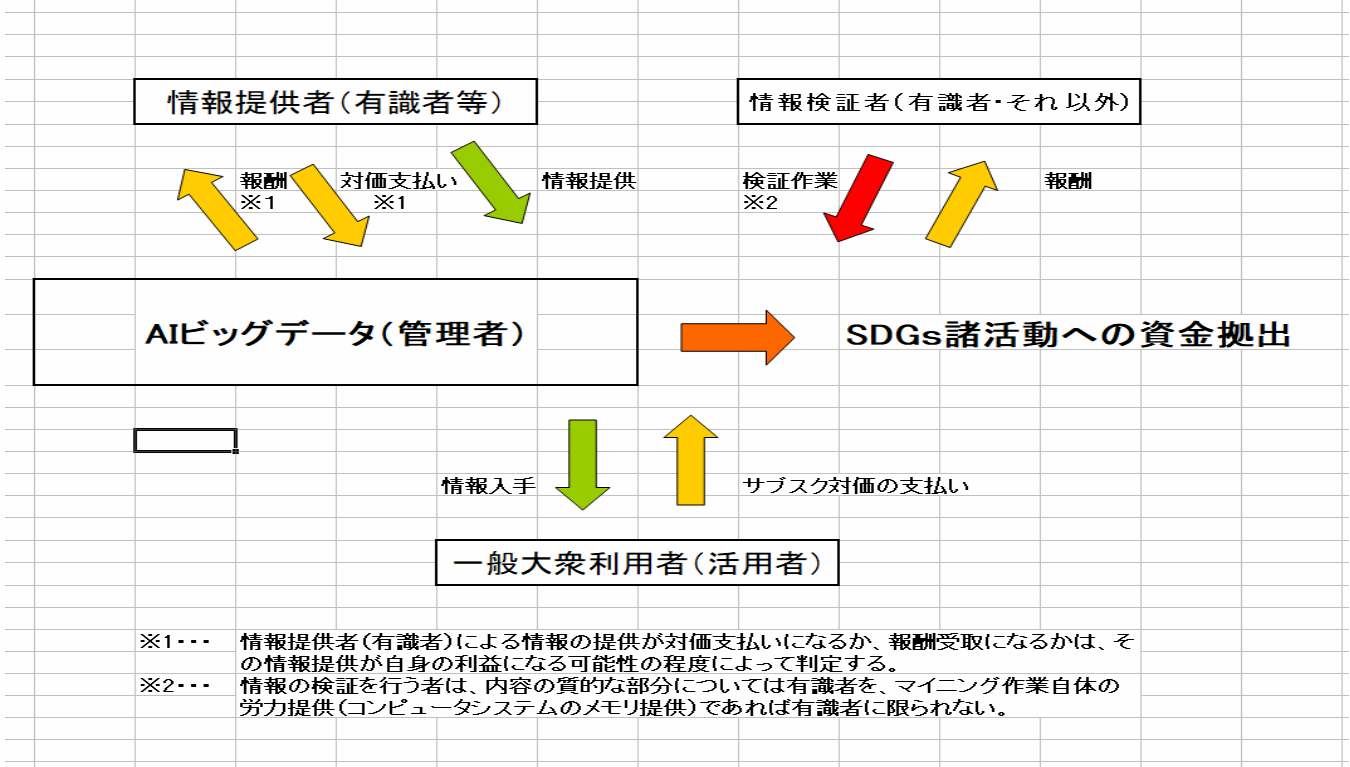
(1) AI技術を駆使し、社会のあらゆる階層、立場、職業の人が、容易に自己の求める知識を引き出すことができるシステムおよびロジック構成とする。
(2) データへのアクセス権をサブスクリプション(月額定額制)方式とし、活用者との契約の際に、「支払った対価の使途はSDGs関連活動への融資資金の原資に充てる」ことを誓約させる。→利用者の間接的なSDGs活動への貢献を実現
(3) AIビッグデータに「自立性」を持たせるため、新しいデータの追加または上書き提供に当たっては、自己の目的のために提供する場合には「対価の支払い」を、公共の利益のために提供する場合には「報酬の受け取り」を行為者に賦課し、または享受させることとする。
(4) 格納データの内、原始記録を書き換えられては事後不都合が生じるデータ(例えば、血液検査における各指標の基準値であったり、その年の特定の場所の公示地価、法定貸付金利、企業業績における基本的データや不動産登記情報など)については、事後の書き換えを防止するために「ブロックチェーン理論」を活用するなどして、情報の安定性を確保するなどの観点も必要となってくる。その際のマイニング作業(情報検証作業)を負担する者には報酬を支払うなどの対応が必要と考える。
(5) 世の中に無数に存在するLANやWANネットワークとの接続可能性をどの程度に設定するかが最大のキーポイントとなるが、今後の時代の趨勢に応じて可能性を広げていけるような基本設定にしておく。
上記を踏まえた全体的なイメージ図
3、今後の課題
「AIビッグデータ」を効果的に運用し、資金を調達するためには、実に様々な課題があるが、それについては以下のような項目が想定される。
(1) システム構築にあたっての難易度の高さ及び初期パラメータの設定レベル
(2) 維持運営コストの可能な限りの低減策
(3) AIによる、個々のニーズに見合った情報の組み換え精度の設定のレベル
(4) その他更新(情報提供)作業やマイニング作業に対する対価設定
1人がサポートしています
2.20 ALIS 1.35 ALIS 0.00 ALIS 












