 81.92 ALIS
81.92 ALIS  0.00 ALIS
0.00 ALIS 

最近よく耳にするMachine Learning(機械学習)がもたらした技術であり、Aという人が写っている映像にBという人の顔を載せるというディープフェイク。難しいことを理解するのが趣味で、先日ディープフェイクについて少し調べてみました。
彼女に説明しようとしたらうまく理解してくれなかったため、記事を書くことにしました。だから、この記事ではディープフェイクがどのように作られるかについて分かりやすく説明します。ニューラルネットワークの要素なども入っているし、機械学習という概念自体の理解も少し深まると思います。
ALISではテクニカルな話が好きな人が多いし、プログラマーも結構いるから、この記事に触発されて機械学習で遊んできた〜!という記事が出てきたらいいなと思います。以外と簡単だそうです。
早速ディープフェクの具体例を見てみましょう。下は、エイミー・アダムスの代わりにニコラス・ケイジの顔を載せたディープフェイクです。

ディープフェイクのすごいところは、上の例のように、Aという顔の角度、表情や照明に合わせて、Bという顔を完璧に自動的に入れ替えることができることです。
ディープフェイクの作り方は驚くほど簡単です。入れ替えたいAとBという人の顔の写真を出来るだけたくさん集めます (出来るだけ多くの顔の角度と表情の写真を用意するのがポイントです)。この写真をアルゴリズムに渡します。アルゴリズムが顔認証を使って、それぞれの画像を少し歪ませてエンコード(符号化。単純化という風に想像すると分かりやすい)します。次に、この顔の単純化されたデータを基に、デコーダ(復号)アルゴリズムで元に戻します。ディープフェイクでは、Aの顔を復号するために学習させたデコーダにBという人の画像を入れます。結果は、Bという人の画像の顔がAという人になります。
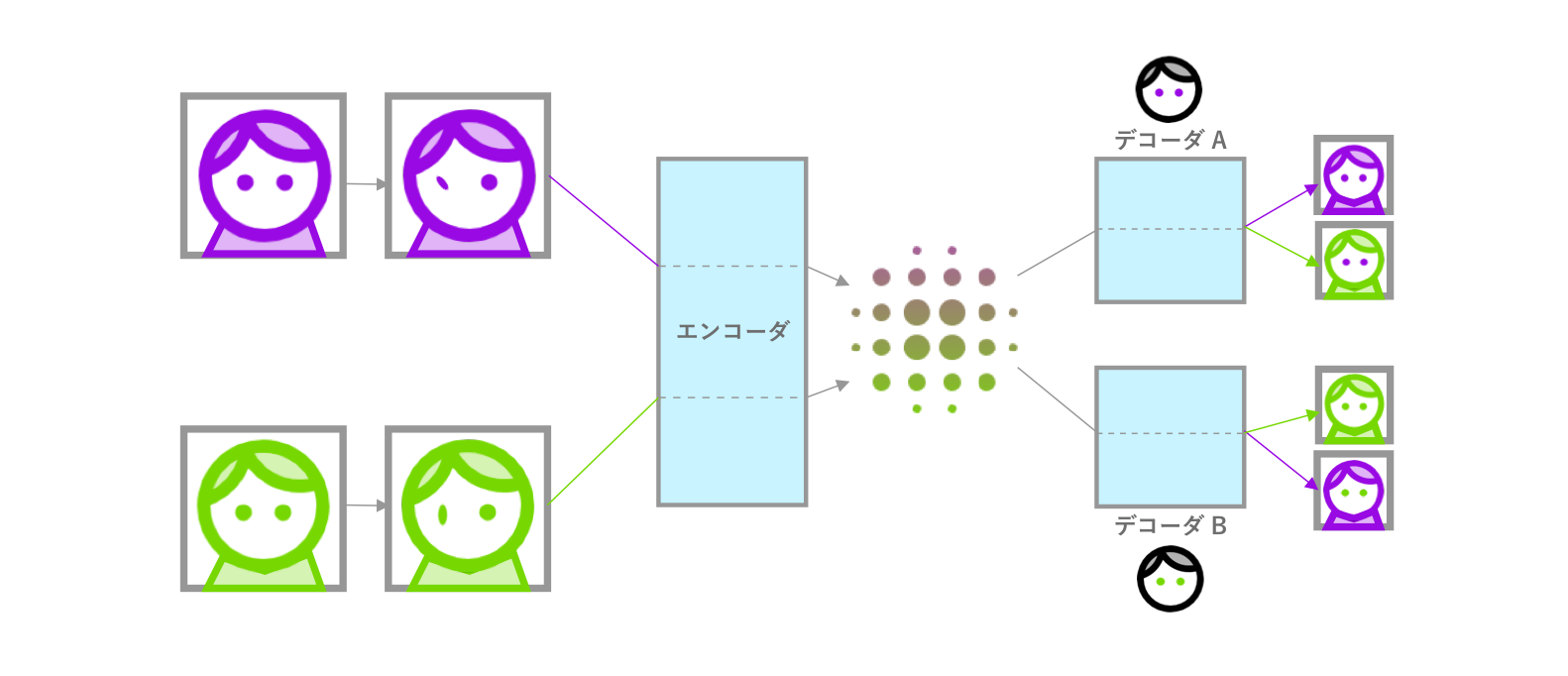
上記をもう少し噛み砕いてみてみましょう。
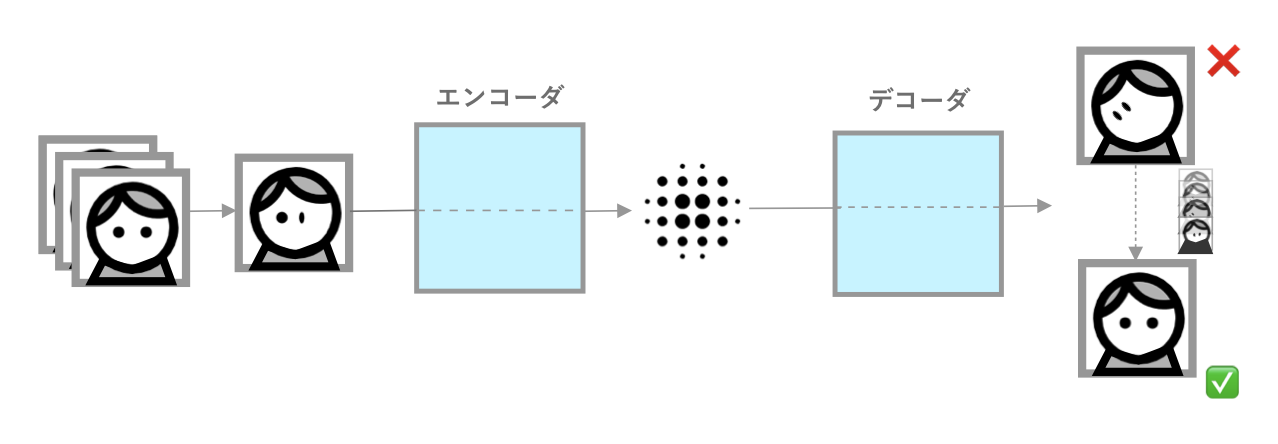
まず、Aという人の顔の特徴を分かるようにアルゴリズムを学習させます。この学習というプロセスは機械学習の原理です。データを入れるとアルゴリズムが勝手に符号化した画像を復号できるように学習するからです。この学習は次のように行われます。
顔を歪ませた画像がエンコーダにより符号化されます。復号するために必要不可欠の特徴だけ残すという単純化です。次にデコーダがそのデータを基に画像を元(歪んでいない方)に戻そうとします。その結果を歪んでいない元の画像と比較します。顔の特徴をうまく捉えられて、うまく復号できるために、アルゴリズムが勝手に自分の様々なパラメータ(ラジオの摘みを想像すると分かりやすい)を調節し、これを何回も繰り返します。もちろん、画像データが多ければ多いほど、デコーダの性能が上がります。これを何回も繰り返すことによって、歪んだ顔の写真がどんどん綺麗に歪んでいない方に復元されます。
上記説明したプロセスでは、アルゴリズムが特定な1人の顔を復号するために学習させられます (A→A)。しかし、ディープフェイクでは、Aという人にBという人の顔の貼っつけることが目的です (A→B)。これをできるために、デコーダはAとB、顔ぞれぞれですが、エンコーダは同じやつを使います。これにより、AとBのそれぞれの独特な特徴を無視し、共通する特徴だけ捉えられるようになります。
学習プロセスでは、AとBの顔は両方同じような形に符号化されるため、その符号化のデータをどちらのデコーダに入れても、そのデコーダが学習した顔を復号できます。つまり、Aという人の画像をBのデコーダで復号すると、Aの顔がBという顔になり、ディープフェイクが完成します。
この記事では最近よく話題になるディープフェイクを分かりやすく説明してみました。あまり時間がなくて、急いで書いた文章なので日本語のミスをお許しください。
では!
※補足
・ このアカウントが作成した記事にトークンは付与されません
・ このアカウントが作成した記事は人気記事に表示されません
2人がサポートしています
32.10 ALIS














