 127.40 ALIS
127.40 ALIS  0.10 ALIS
0.10 ALIS 

おはようございます。
この時期に風邪(のような症状)が今週発現。いやだなと思いながら安静に過ごしていたら、良くなったなーと思ったのに。熱計ったら昨日まで無かった熱が・・・。
ただの風邪の可能性も高いので、落ち着いて安静にします。
今日も、情報技術者試験の話から離れて、機械学習について書きたいと思います。
といっても、そもそも僕もPython初心者に毛が生えた程度のレベルであり、AIについて何かを語れるほど詳しいわけではありません。
むしろ、だからこそそんな自分でも簡単に「やってみることができる」Pythonはすごいなーと思う訳です。機械学習のためのパッケージや様々なモジュールをインストールやimportするだけで、出来ちゃうわけです。
PyQで過去短期間で詰め込み学習しましたが、今回Udemyで改めて勉強して、少し自分の身についてので、是非みなさんもやってみてくださいということで書いていきます。機械学習自体の細かい解説は、他のサイトや他の学習手段を利用ください。あしからず。
なんでもツールを利用すること自体は、そんなに難しくないですよね。本当に難しいのは、「何故そうなるのか?」の原理をきちんと理解して、「こう活用しよう」と応用できることですね。ただ、いきなりそのレベルにいける人なんていないので、まずはやってみないことには始まらないということです。
すでにPythonをインストールしている人も、そうでない人も、Anacondaを未インストールの場合は、Anacondaで実施することがオススメです。
➀ 必要なものがすぐに揃う
機械学習をやろうとすると、Pythonの標準ライブラリ―にないパッケージ(numpy, jupyter notebook, scikitlearn, pandas等)を使います。
pip install等で全部個別に用意しても全然問題ないのですが(ボクもPythonを単体でInstallしていたので、初めそうしました)、Anacondaだと初めからほぼ必要なものが揃っているので圧倒的に便利です。
僕も今では、もともとインストールしていたPythonは、Anacondaを起動するのが面倒な時に、コマンドプロンプトから呼び出して、書こうと思っているプログラムが正しいか検証するくらいの目的で使う程度です。(笑)
➁ 仮想環境が簡単に作成可能
先ほどのように、必要な外部パッケージをインストールしたり、機械学習に必要なデータや画像を格納したり、また、作成したモデルをWEBアプリケーションとして公開(デプロイ)したい、、、等、先を見据えた際に仮想環境が簡単に作成できるのがとても便利です。
僕も初めはvirtualenvで仮想環境を作ってましたが、Windowsだと上手くできず(多分僕の問題です)、わざわざUbuntuをインストールしてやったのですが、いちいち仮想環境をOnにしたりだの、兎に角面倒でした。
➂ WEBアプリケーション作成に繋がる
➁にも書いたWEBアプリケーションとしての公開ですが、PythonのWEBフレームワークDjangoを利用して、WEBページ・アプリケーションを作成する際もAnacondaにあるSpyderやVisualCodeStudioを使うととても便利です。
複数のファイルをフォルダを触るので、一覧を見ながら個々のファイルを触れるからです。

もちろん、Anacondaでなくても大丈夫です。僕も初めは、Anaconda使ってませんでしたが・・・。たまたまかもしれませんが、どれだけ便利なのか、何故Anacondaなのかって説明に巡り合わなかったんですよね・・・。
Anacondaのサイトにいったら、トップページのナビゲーションバーにあるDownloadを選択します。

ページが遷移したら、スクロールバーで下の方に行くと、以下のボタンに行きつきます。ご自分のOSに合わせてDownloadをしてください。
Downloadが完了すると、このような画面が出てきます。
次に規約についての同意を求められますので、がっつり合意しませう。(I Agree!)
個人利用なので、次はJust meを選択
次にどこにインストールするかを聞かれますが、特にデフォルトから変えずでいいと思います。
その次にPATH(環境変数)にAnacondaのフォルダを追加するか聞かれる上のチェックはブランクのままでOK。
その下のAnacondaのPythonをデフォルトのPythonとして利用するかについては、特段避ける理由がなければチェックありのままでOK。
そこまで来たら、インストールが始まります。
インストールが完了したら、AnacondaのフォルダにあるAnacondaナビゲーターを起動してください。

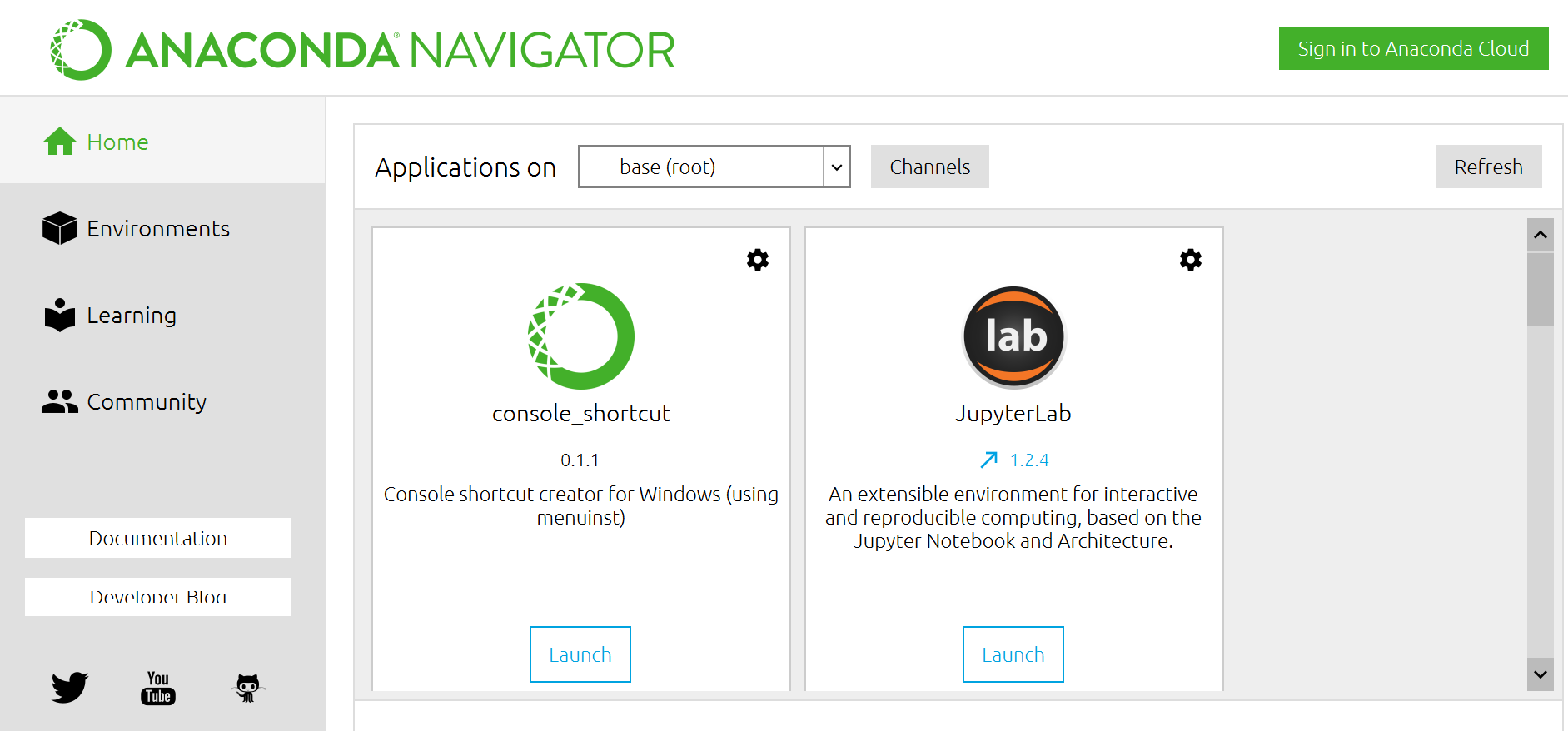
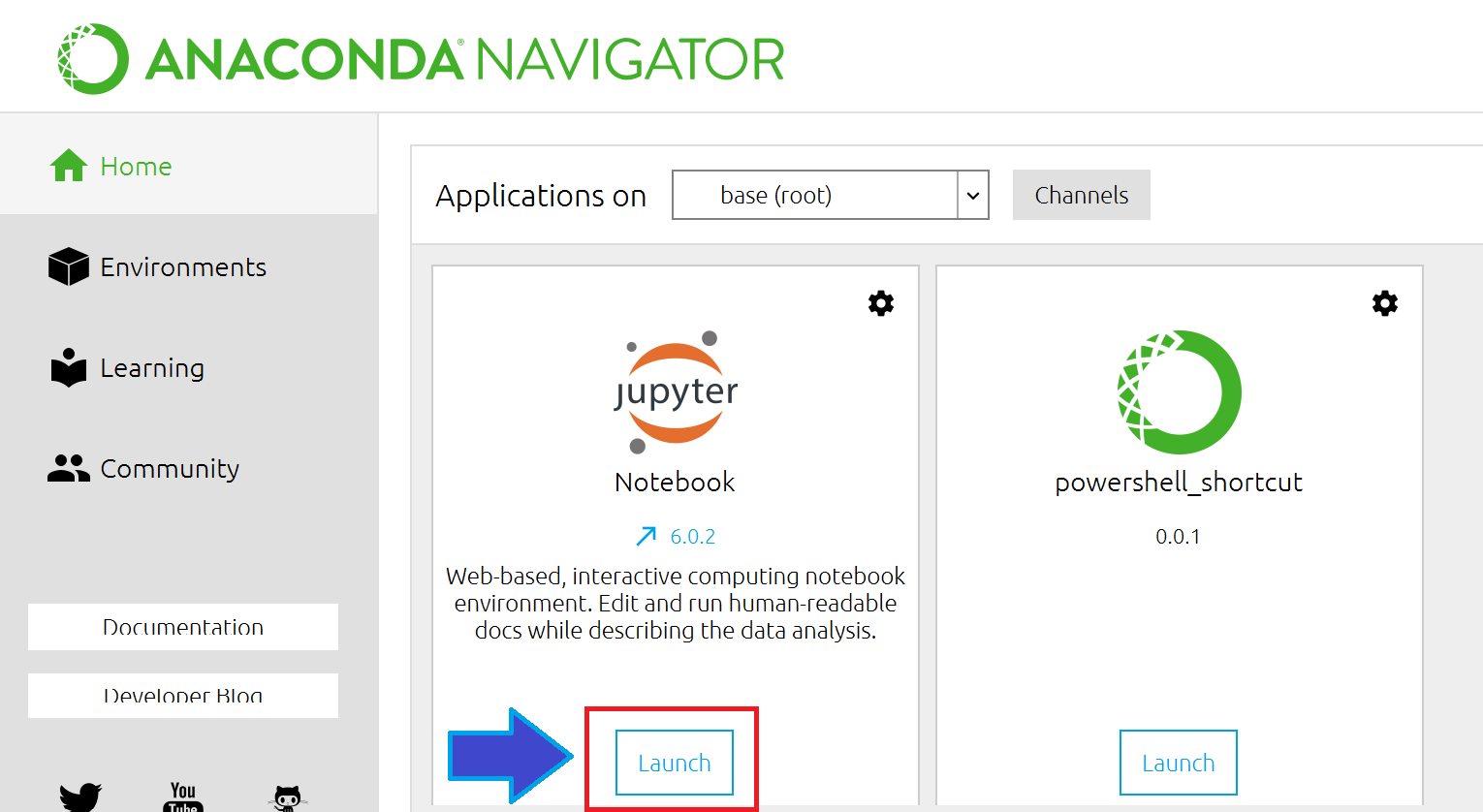
こんな感じで画面が開きますので、右側のスクロールバーをちょっと下に下げて、jupyter Notebookが出てきたら、Launchを押して開きます。
ちなみにLaunchというのは、新サービスを世に送り出すという意味で用いられるそうですが、この場合は開始するくらいの意味ですかね。どうでもいいですか。そうですか・・・。(シュン・・・)
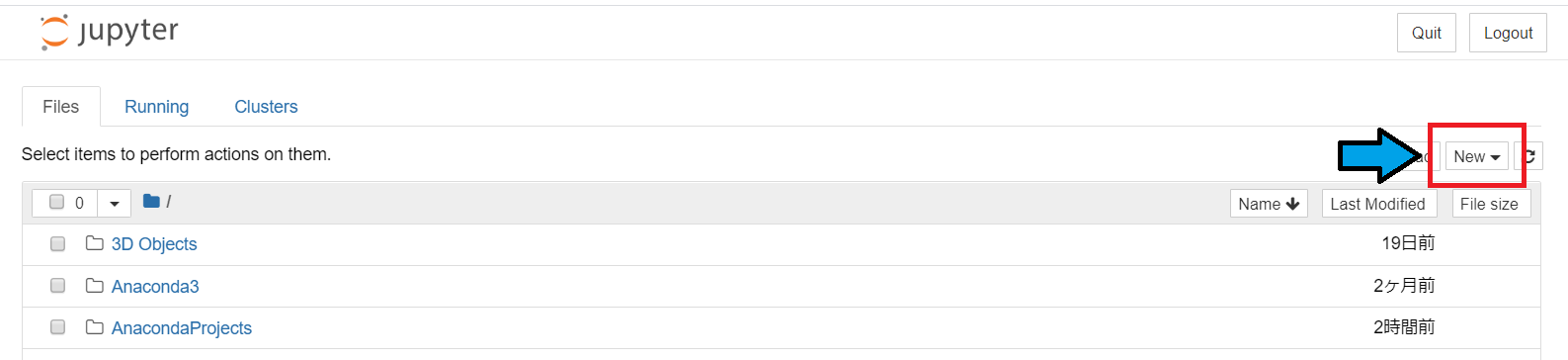
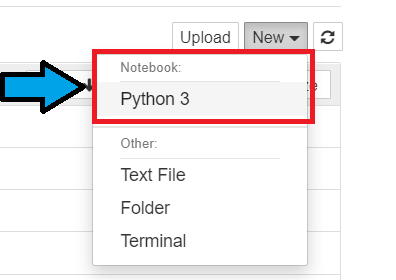
そうすると、こんな感じになると思うので、右側のNewボタンからPython3ファイルを選んでください。
そうすると、こんな画面が開きます。ここまで来たら準備はOKです!!

※ちなみにカーソルが入っている部分をセルといい、セルには1行でも複数行でもコードが書けます。実行する時は、一般的にShiftキー+Enterキーでセル単位の実行が可能です!試しに、print('Hello World')や1 + 1など、実行してみてください。
➀ 機械学習
正直、僕は数学が大の苦手の文系男です。(文系の勉強もロクにしませんでしたが・・・) なので、超おおざっぱにしか説明できないことをここに宣言しますが、簡単に言うと、過去の実績から将来を予測することを機械学習で行う。
そして、その予測の仕方は、過去の原因となる数値(係数)と結果として出た数値の関係から、別の数値(係数)から予測される結果を導きだすことです。この係数を説明変数、予測する値(結果)を目的変数といいます。
まあ、Anacondaまでインストールさせといて、項番4でそこ説明するかって話ですよね。いいんです!僕もざっくりしか分からないんだから。
➁ 線形回帰
グラフを思い浮かべてください。x軸に原因となる係数をy軸に結果をおいた場合に、x軸とy軸の交点が直線となった状態。それが線形回帰です。
なんのこっちゃ?という感じでしょうか。僕もです。つまりこんな感じです。
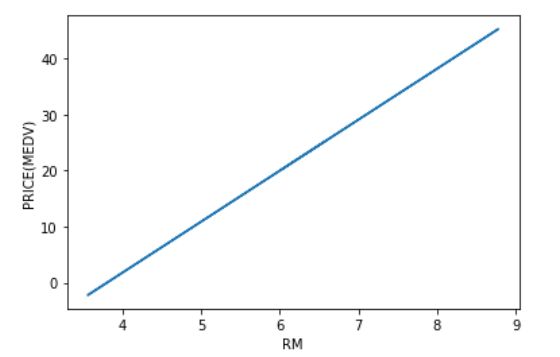
x軸RM(部屋数)に対する、y軸不動産価格を表しています。
当然これは結果で、この元になる数値はもっとてんでバラバラです。ただ、傾向としてこの線のまわりに実績値が存在する訳です。実績値は以下のとおりです。
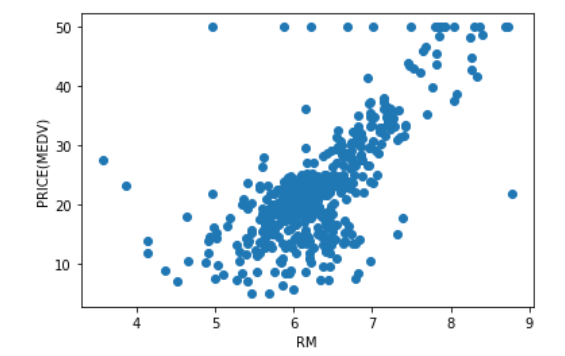
点は点在していますが、傾向から言うと先ほどの直線の周りに存在していますよね。
これは機械学習のうち、「教師あり学習」といって原因と結果から正解を導き出すためのモデルを作り、そのモデルに当てはめることで正解を予測するという行為なのです。なんとなく分かりました?
憶ラビット(@ocrybit)さんが、ALiSへのコード記述を可能にしてくれたようで、ずっと書きたかったんです。昨日の夜から、正直Anacondaのインストール方法とか、もう書きながら、早くALiSにコードが書きたくてしょうがありませんでした。(笑)
jupyterのセル単位ってイメージで書いていきますね。
%matplotlib inline
%config Inlinebackend.figure_format = "retina"
import matplotlib.pyplot as plt
import pandas as pd
from sklearn import linear_modelまずは、グラフを記載するためのmatplotlibというモジュールを使ってnotebook上でグラフを描画するためのマジックコマンド"%matplotlib inline"と、高解像度でグラフ表示をするためのマジックコマンド"%config Inlinebackend.figure_format = "retina""を記載します。
次の3行で必要なモジュールをインポートしています。matplotlibはグラフ描画のためのモジュールで、matplotlib.pyplotというモジュールをpltという名前で利用できるようにas pltと書いています。
pandasは係数や結果データを、データフレーム(データテーブルみたいなもの)で管理したり必要な値を取り出したりするために使います。これもプログラム中でpdと短い記述で使えるようにas pdとしています。
最後にscikitlearnという機械学習用のパッケージをインポートしていますが、簡単に言うと、sklearnというフォルダから、linear_modelというモジュールを呼び出しています。from ~ の ~ はフォルダ名です。linear_modelというのは先ほど説明した線形回帰分析のためのモジュールです。
これでNotebookに必要となるモジュールは用意ができましたので、次に分析の対象とするデータを用意します。
データを格納するためのツール(pandas)、分析するためのツール(linear_model)と,分析結果を描画するためのツール(matplotlib)は揃いましたが、完全のデータがありません。(笑)
僕は完全なる非エンジニアなので、機械学習の実務まで分かりませんが、おそらく基礎となるデータを社内の情報システムから収集してきたり、画像分析であれば画像ファイルをインターネットから収集したりする感じでしょう。
実は機械学習用のサンプルデータがscikitlearnには用意されています。(あら素敵)
7つくらい種類があるのですが、今回はBostonの住宅情報に関するデータを利用したいと思います。
from sklearn.datasets import load_boston
boston = load_boston
x = boston.data
y = boston.target
df = pd.DataFrame(x, columns = boston.feature_names).assign(MEDV=np.array(y)) 一行目はsklearnフォルダは以下のdatasetsフォルダからボストン住宅価格データをimportしています。

自身のAnaconda3のフォルダ中のsklearnフォルダ配下(datasets>data)にboston_house_prices.csvやbreast_cancer.csv、wine_data.csvが格納されているのが調べてみると分かると思います。
このcsvファイルを読み込む処理を指示しているのです。
boston = load_bostonで読み込んだデータをbostonという変数に格納しています。
次のx = boston.dataは線形回帰を行うにあたっての説明変数となりえる13項目のデータ部分を行列形式でxという変数に格納しています。
y = boston.target は線形回帰を行うにあたっての目的変数をyという変数に格納しています。では、試しに変数xを出力してみましょう。

何やら、ごちゃごちゃと表示されて「うわぁ・・・(どん引き)」となる方も多いですが、僕もその一人です。(!)
これはnumpyというPythonの外部モジュールで、多次元配列という複数次元の配列です。簡単にいうと、13項目のデータ値が配列形式で、xという上位の配列にに格納されているといったイメージです。

多次元リストっていうとイメージしやすいですかね?
最後のdf = pd.DataFrame(x, columns = boston.feature_names).assign(MEDV=np.array(y)) はxとyに格納したデータを一覧表(データフレーム)にすべく、pandasというモジュールを使っています。
xに格納された13項目の値に、columns = boston.feature_namesで項目名称を付け(先ほどxを出力した際、値しかありませんでしたね)、.assignという処理でMEDVという項目名でyに格納していたデータをデータフレームに列追加しています。
これで、データフレームが出来上がりました。試しにdfを出力してみましょう。
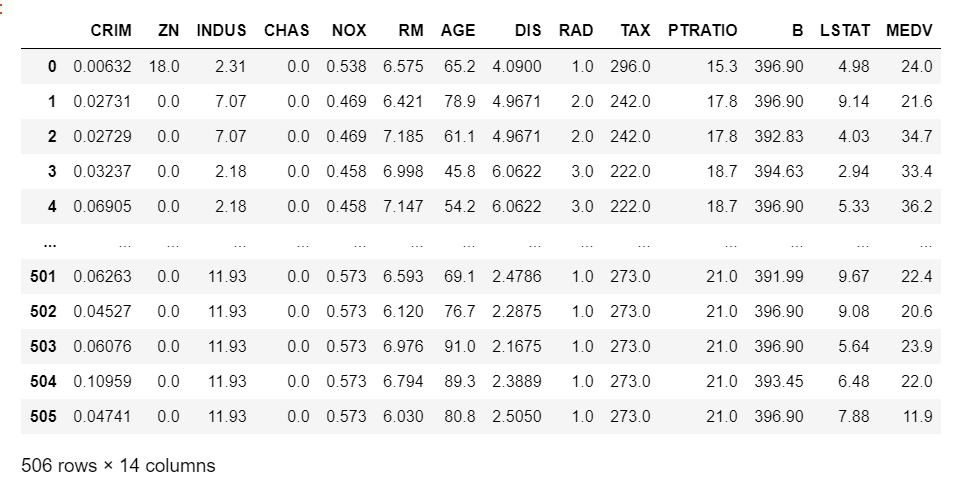
きちんとデータフレームができていますね。ちなみに13項目ですが、CRIMは犯罪発生率、ZNは宅地比率・・・となっており、MEDVが住宅価格です。(×1,000ドル)
今回は、説明変数をRM(部屋数)としたモデルを作成します。
x_value = df[['RM']].values
y_value = df[['MEDV']].values
model = LinearRegression()
model.fit(x_value, y_value)x_valueという変数にデータフレームのRMの列に存在する値を格納、y_valueという変数にデータフレームのMEDVの列に存在する値を格納します。
次にmodelとう変数に、初めにインポートしておいた、linear_modelのLinearRegression()(線形回帰分析モデル)を格納し、model.fitとして、それぞれ説明変数にx_value(RMの値)、目的変数としてy_value(MEDVの値)を与えます。
これで学習完了です。
※通常はデータセットの8割をテストデータ、残り2割を検証用データとして分けて作ったモデルの検証をするそうです。
では、部屋数(RM)が10だった場合の住宅価格(MEDV)を予測してみましょう。
model.predict([[10]])と入力してみてください。
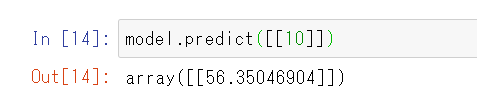
予測結果は約56千ドルとなりました。
では、今回の元データの値をもとに散布図と、予測結果をグラフ描画してみましょう。
plt.scatter(x_value,y_value,c = "blue")
plt.plot(x_value, model.predict(x_value),c = "red")
plt.xlabel("RM")
plt.ylabel("PRICE(MEDV)")
plt.show()plt.scatterが散布図の出力指示で、x軸にx_value、y軸にy_valueをセットし、青色で描画されるようにしています。plt.plotは折れ線グラフを、x軸にx_value、y軸はx_valueをもとにしたモデルでの予測結果とし、赤色で描画されるようにしています。
x軸の名称を”RM"、y軸の名称を”MEDV”とし、plt.show()でグラフ描画をします。
そうすると・・・
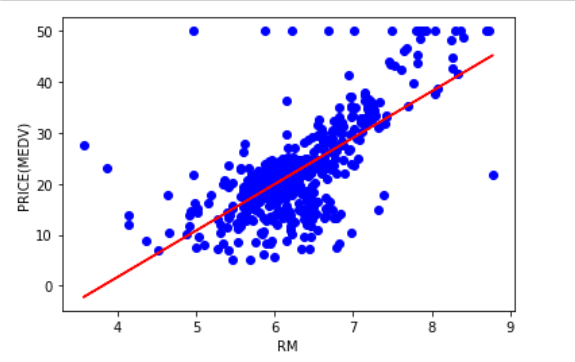
グラフ描画ができました。部屋数(RM)が10の場合に56千ドルというのは、妥当そうな数字ですね。
もう一度念のため、言いますが僕は機械学習の数パーセントも理解できていないと思います。それでも、データがあってツールが使えればこうして実行できる訳です。
やりもせずに、なんとなく難しそうと敬遠していることはとても勿体ないなーということをお伝えできれば、嬉しいなあと思います。
また、勉強しても使ってみないと次の瞬間からすぐ知識は風化し、また分かった気がした内容はなんだっけな?になっちゃいます。
是非、何らかの形で自分でも実行・望ましいのはアウトプットまでするといつの間にか身につくかなーと思います。
最後まで読んでいただきありがとうございました!!!
↓コード全文
10人がサポートしています
124.82 ALIS













