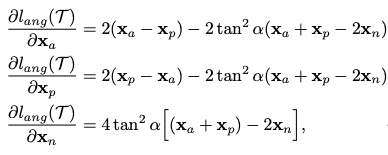54.82 ALIS
54.82 ALIS  0.00 ALIS
0.00 ALIS 
- インターンシップで2週間metric learningをやったのでサーベイ結果をまとめます.
- 論文と手法紹介をこの記事でして,実験はまた別記事で行います
- N-pair SamplingとAngular LossによるMetric Learningがおそらくもっとも安定位していて良い
- N-pair Sampling, N-pair Loss
- Metric Learningは類似度や距離を定義し,それらが近いものでクラスタリングする手法です.
- Deep Metric Learningは,距離の定義と抽出をDNNによって行おうというものです.
- 画像データだとPretrainedのCNNを用いて特徴抽出をし,その後ろにfc層を置き,任意の次元に出力するような設計が一般的になると思われます.
- 詳しくはこちらを参照してくださいhttps://techblog.zozo.com/entry/metric_learning
この手法は,ランダムに取得したデータx,xと同じラベルのデータx_p,xと異なるラベルのデータx_nの3つをセットにして学習を行います.
以下のlossを最小化するよう学習します.このf(x)は,DNNによって抽出された任意の次元の出力です.
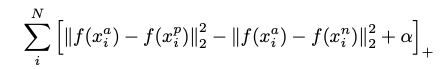
この式から同じラベル同士のペアの距離を近づけ,異なるラベル同士を離すような学習をすることがわかります.また,αはハイパーパラメータで論文中の実験ではα=0.2と設定されていました.このαは,2つのラベルをどの程度離すかを設定するパラメータです.
先ほどのTripletを改良したものがこのN-pairです.
TripletにおけるnegativeサンプルをN個(ハイパーパラメータで分類したいクラス数にもよるが比較的多めにとると良さそう)にしたバージョンです.
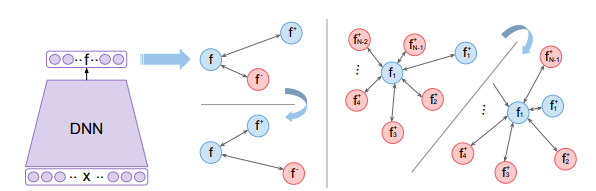
N個の異なるラベルのnegativeサンプルを用いることで,ひとつのpositiveサンプルに対して,各negativeクラス間の相対的な位置関係がわかりやすくなり,学習が安定するのかなと思われます.
今回のインターンシップでは犬猫の2値分類であり,異常とするデータが非常に少なかったため,さしてうまく作用すると思えなかったため使用しませんでした.
これは抽出されたmetricをnormalizeし,そのmetrciを用いて分類問題を解き,そのlossを流して学習する手法です.
L2正則化を加えることで超球面上にmetricを配置することになり,通常の学習よりも安定するということだと思われます.
論文:https://arxiv.org/abs/1708.01682
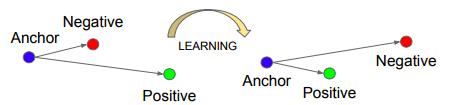
anchorとpositiveとnegativeの3点を角度の視点から距離を離すように設計されたlossです.文章だけで説明するのが難しいのと,論文が非常に読みやすいわかりやすい良い論文なので,ぜひ論文をよでみてください.
実装自体は非常に簡単なのでウルトラおすすめです.
結果だけ言うと,以下の式を最小化するよう学習します.
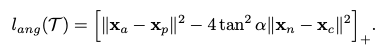
それによって,各微分にanchor, positive, negativeが存在するので,学習が効率よく精度よく進むよと言うことにも言及されています.