54.82 ALIS
54.82 ALIS  0.00 ALIS
0.00 ALIS 
進化が早すぎるDeep Learning技術を追うために,毎日1本論文読みチャレンジをはじめましたホエイです.
Image Recognition,Semantic Segmentationを極めるべく,画像認識タスクで圧倒的な成功を収めているResNet周辺の論文を読んでいたのでここにまとめます.また,随時追加していきます.
以下が読んだ論文のジャンル別一覧です.
## ResNetとResNet亜種
- (ResNet)Deep Residual Learning for Image Recognition
- (ResNeXt)Aggregated Residual Transformations for Deep Neural Networks
- (Wide-ResNet)Wide Residual Networks
- (PyramidNet)Deep Pyramidal Residual Networks
## ResNetのモジュール
- (SENet)Squeeze-and-Excitation Networks
- (scSENet)Concurrent Spatial and Channel ‘Squeeze & Excitation’ in Fully Convolutional Networks
## ResNetでの正則化
- Deep Networks with Stochastic Depth

## ResNetとResNet亜種
### ResNet
CNNは層を重ねれば重ねるほど高次元の特徴を獲得していくので,画像認識タスクの精度を上げるにはいかにして層を増やすかという時代がありました.その時代において,大きなブレイクスルーとなったのがこのResNetです.
ILSVRCという毎年開催されるImageNetを用いた画像分類(物体検出など他の部門もあるが,最も話題になるのは分類タスク)において,ResNetが登場する2015年まではせいぜい20層程度(VGGが16層,GoogleNetが22層)のモデルで争っていました.それ以上に層を深くしてしまうと勾配消失問題(vanishing gradient problem)により学習が非常に困難になるという問題があったためです.
しかしResNetは152層もの層を重ねることに成功し,ILSVRC2015年の優勝モデルとなりました.
ここまで多くの層を重ねて学習がうまくいき,また当時のSOTA(State Of The Art)を達成した大きな理由が,shortcut connectionです.残差ブロック(residual block)と呼ばれる機構を導入することで,backpropagation時に勾配が各層に直接流れるようになり,勾配消失問題を解決しました.
また残差ブロックではその名の通り,直前の予測値で生じた誤差を予測することになるので,単一のモデル内でアンサンブル学習を行うような効果が生じます.(GBDTみたいなイメージ?)
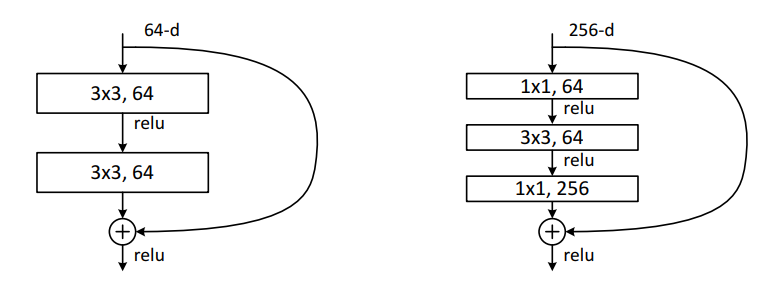
左が通常のresidual blockで右がbottleneck構造.同じパラメータ数でより多くの層を重ねることが可能であり,表現力の向上を見込めます.
### ResNeXt
ResNetのbottleneck blockをいくつか枝分かれさせたあとに足し合わせる構造を導入したモデルがResNeXtです.枝分かれの部分に新たな次元を追加したという意味でNeXtというネーミングになっています.また,このような構造から論文中ではNetwork in Neuronと名付けられています.
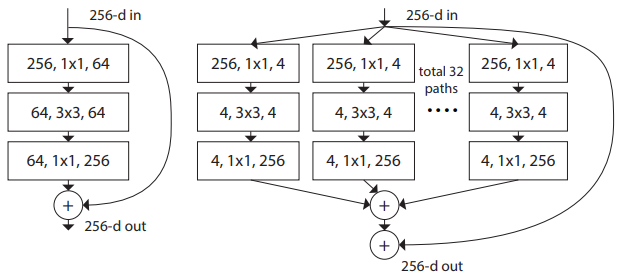
そしてこの新たな次元をcardinalityと呼び,同じパラメータ数であればNNの層を増やすよりも,この次元を大きくしたほうが効率よくモデルのキャパシティを高くすることが実験的にわかっています.
ResNetは層方向にアンサンブルしているのに対して,ResNeXtは各ブロックでaveragingのようなアンサンブルを実現しているということだと思われます(所感).
### Wide-ResNet
端的に言うと層数を減らし,その分channel数を増やしたResNetです.
ResNetの層はほとんどが良い特徴を獲得できておらず,いくつかの層を削除してもあまり精度に変化がないことが分かっています.
そして,ResNetの精度を生み出しているのは大量の層の数ではなく,residual moduleそれ自体なのではないかという仮説の元,提案されたのがWIde-ResNetです.論文中では通常のResNetのchannel数をk倍しており,k=10の28層で最も良い精度を出しています.
またchannel数を増やすことは,層を増やすよりも計算コスト的にかなり低くなる(行列計算としてまとめられる)ため,精度・計算コストの両方で非常に優れたネットワークになってます.
### PyramidNet
先ほど述べた通り,ResNetはダウンサンプリングを行ってchannle数を増加させている部分以外では,重要な特徴を獲得できていないという問題に対応すべく提案されているのがこのPyramidNetです.
ダウンサンプリングを行う層でのみchannel数を倍増させるのではなく,各層で徐々にchannel数を増やすというアイデアを用いており,通常のResNetに比べて各層がより有効な特徴を獲得できることになります.
層は下の図のように線形に増加させる方法と指数的に増加させる方法の2通りが提案されています.
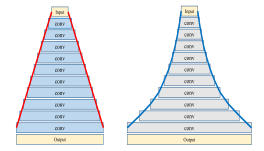
ただどのように層を徐々に増加させていくかというハイパーパラメータが生じるため少し使いずらそうな印象を受けますが,実験の成績はパラメータ数が同程度のWide-ResNetよりも非常に良い結果になっています.
## ResNetのモジュール
### SENet
SENetはILSVRCの2017年優勝モデルで,特徴マップにチャネル間の重み付けを行うAttention機構を加えたモデルです.Global Average Poolingによって各チャネルの代表値を取得し,Dense->ReLU->Dense->Sigmoidとつないだのちに,元の入力にかけ合わせます.
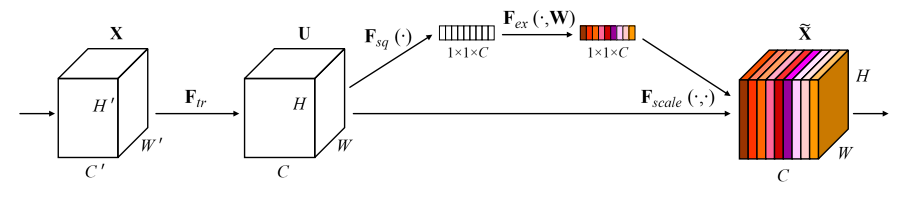
この機構に関してはResNetだけではなく,他のCNNにでも簡易に導入できることも魅力のひとつです.
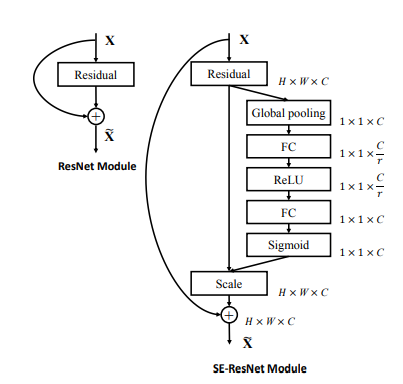
ただしこの機構はチャネル間の特徴をより鮮明化するものなので,画像分類タスクでは非常に大きな精度の向上をもたらしますが,セマンティックセグメンテーションにおいてはそれほど大きな精度の向上は実現できませんでした.そしてそのことがセマンティックセグメンテーションでも精度を向上させるAttention機構であるscSENetにつながっていきます.
### scSE module
SE moduleは各チャネルの重み付けを行うためcSEと論文中で呼ばれ,新たに各ピクセル間の重み付けを行うsSEという機構を導入し,それらを両方同時に使用したのがこのscSE moduleです.
これにより各ピクセル間の特徴をenhanceすることができ,セマンティックセグメンテーションでも非常に大きな精度の向上を果たすことが可能になりました.
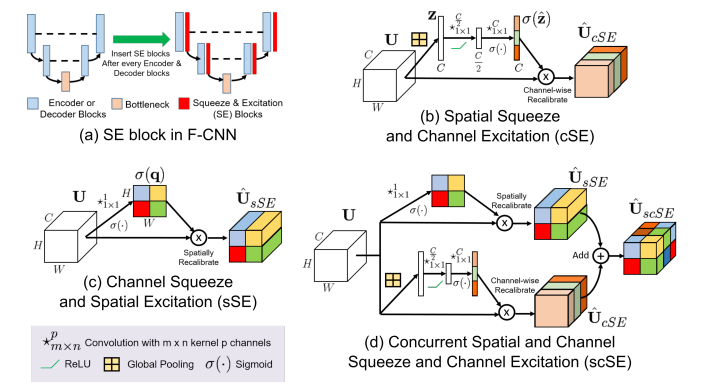
- cSE
x = GAP(input_x)
x = Dense(x)
x = ReLU(x)
x = Dense(x)
x = Sigmoid(x)
out = mul([input_x, x])
- sSE
x = Conv(filters=1, kernel_size=1, stride=1)(input_x)
x = Sigmoid(x)
out = mul([input_x, x])
- scSE
out = cSE(input_x) + sSE(input_x)
## ResNetにおける正則化
### Stochastic Depth
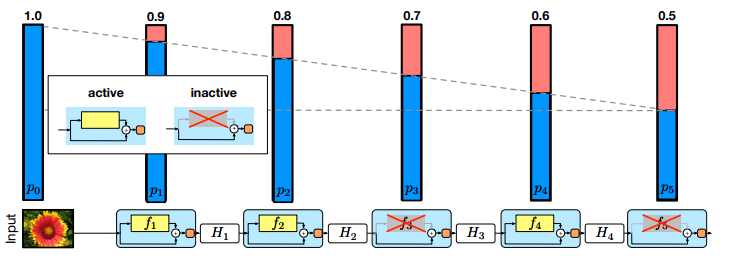
学習時には層が浅く,テスト時には層が深い夢のようなネットワークを実現します.
ResNetの多くの層で十分な特徴が得られていないことを利用した正則化手法で,学習時に各ミニバッチごとに各層をランダムにスキップ(identity mappingのみ)します.これにより通常のDropoutよりもよりよくoverfittingを抑えられ,よりよいアンサンブルになります.Dropout同様,テスト時には各出力をp_l倍します.
最終層のスキップする割合(p_L)が0.5のとき,学習時間が通常の75%ほどで済みます.
### Shake-Shake regularization
ネットワーク内でのdata augmentationで.各層の特徴マップにノイズを与えることで学習データをより多様に見せる手法です.
residual module内で流れを2つに枝分かれさせ,それぞれに0~1の一様分布alpha, (1-alpha)をかけます.backpropagation時には,先ほどとは異なる0~1の一様乱数beta, (1-beta)をかけて逆伝播させます.テスト時には各径路で0.5をかけます.
乱数はミニバッチごとに新規生成し,同一ミニバッチ内の各画像ごとに異なる乱数を用意するのが最も良い精度を出すようです.
通常300epoch程度で学習を終了するCIFAR100で,cosine annealingを用いて徐々に学習率を低減させていきながら,1800epochかけて学習している点からも,data augmentationとして非常に有用な手法であることがわかります.