 454.56 ALIS
454.56 ALIS  124.82 ALIS
124.82 ALIS 
こんにちわ、コロナの影響で目下、絶賛自宅待機中です。
リモートワークの環境が整ってなかったことが功を奏しています。(出勤した時のことを考えると、怖すぎて今は考えたくないけど・・・笑)
今日は、numpy(Pythonの数値計算用外部モジュール)とmatplotlib(グラフ描画モジュール)でヒストグラムを描画することについて書き残します。

そもそも、そんなんいつ、どんな時に使うの?って話ですが、目下色んな本やら何やらで自分でニューラルネットワークを作るってことを学んでいて。
やり方は覚えたのですが、知識定着のため、色々試しています。その中で、画像データを数値(配列)に変換して特徴量※をインプットとして、ディープラーニングをするということをしようとしています。(※色の濃さを数値であらわす)
前段階で、画像の特徴を見るときに、ヒストグラム(散布図)で表すと事前に傾向が把握できますよって解説があったわけです。機械学習自体はヒストグラムはなくてもできると思いますが、どうやって分類をするか事前に考えるのに使えた方が良さそうだから覚えようと思ったのです。
ところが、その解説の中で、あまりにもサラッとコードが並べられて、処理内容についての説明が超絶雑だったのです(泣)
自分で色々調べたり試してちょっと理解できたので、ここに残しておこうという趣旨です。
それ以外にも、例えばテストの結果を視覚化する。(100点が〇人で、85点が〇人で・・・みたいなやつ)なんて使い方もありだと思います。
まずは、コードを先に書きます。ちなみにグラフ描画をするので、Jupyter notebookを使います。
※Anacondaだと、numpyもjupyter notebookも使えるので便利です(不明な方は↓)
前提は以下のとおりとします。
・ -10~10までの範囲の数字を100個。(重複あり)
まずは、数列を用意します。(実際にはJupyter notebookで書きます)
numpyをnp(as np)としてインポートしているので、np.arange()として引数に最小値(-10)・最大値(10)・値の個数(100)を記述してnum変数に格納します。
import numpy as np
#-10から9までの範囲で、100個の数値を用意
num = np.arange(-10, 10 ,100)numの中身を出力してみます。
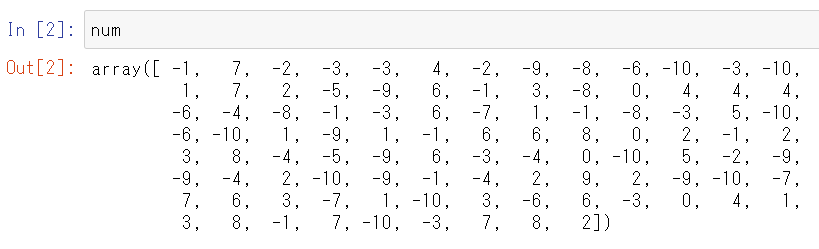
念のため、要素数(数値の数を確認してみます。)

100個ありますね。
次に、numpyのhistogram関数を使って、ヒストグラムにしたいデータを格納します。histという変数に関数の返り値が格納されているので、出力してみます。

1つ目の返り値として、10個の一次元配列(左端が11、右端が7)が出力されました。
2つ目の返り値として、11個の一次元配列(左端が-10、右端が9)が出力されました。
データだけを引数として与えた場合、自動的にbin(階級)を10として、度数を分布させます。(実際はー10から10の範囲なので、1個ずつ数えると20ですが10にまとめた場合の分布となっているのです。)
2つ目の返り値は閾値として、10個のbinに分布する場合にどの数値を境界としているかになります。
では、binを20にしてみます。
改めて、ランダムの配列を作るところから・・・
引数でbinsを指定してみます。

一個目の返り値が20個の配列になりました。
度数の分布が適切かを以下のコードで確認してみます。
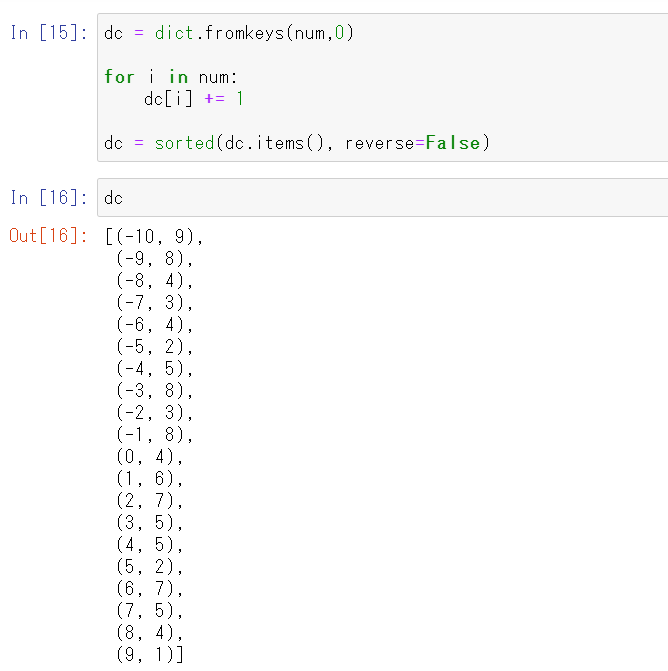
numを辞書型に変換(dict.fromkeys(リスト,要素を0埋め)し、キーに該当した数分、要素に1を加えて集計しています。
サンプルで上の図➊と下の図➋で確認すると、-10が9個、1が6個、5が2個とできてそうです。
では、matplotlibを使ってヒストグラムを描画します。先ほどnumpyのhistogram関数で作成したものがhistという変数に格納されているので、y軸(縦)にhistを、x軸はー10~9までの値なので、x軸に設定する配列を作成します。

では、matplotlibでグラフを描画してみましょう。
※histには返り値が二つあるので、度数を利用する場合はリストの要素を指定するようにhist[0]と記載します。
単純にグラフを書くだけなら、以下の2行でOKです。
plt.bar(x,hist[0])
plt.show()きちんと分布が描画できているか、見るべくメモリを1刻みで描きたいので、以下のようにコードを書きました。
xという変数に-10~9までの1刻みのリストを格納しているので、それぞれx軸・y軸のメモリにセットしてヒストグラムを描画します。
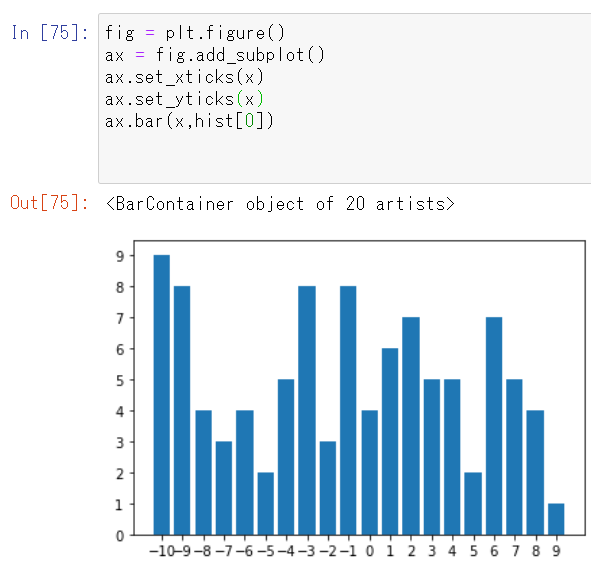
できました。描画できましたね・・・。
完全に忘れていました。
度数分布を得るために書く、numpy.histogram()ですが、実はこんな書き方もできるんです。

度数分布の返り値は全く同じ。異なるのは2つ目の返り値の境界になる値が異なることでしょうか。しかし、グラフの描画結果に差異はありません。
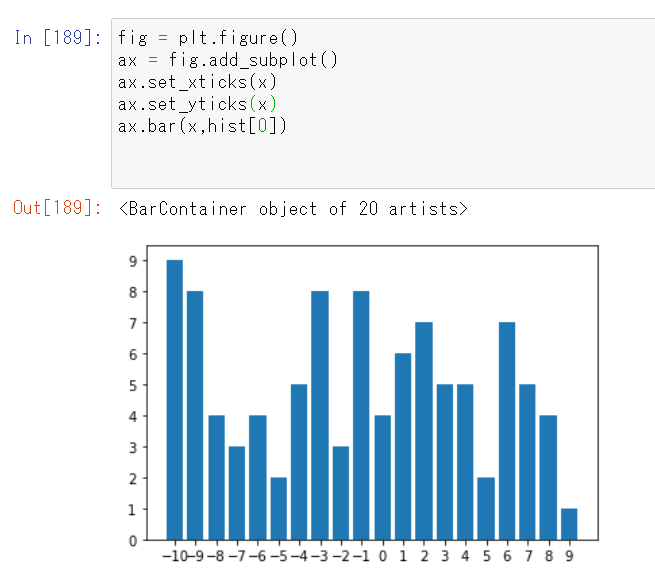
引数に度数分布を得たいデータ(num)と、階級数(20)、分布させる範囲([-10,9])を与えていると、色々試して分かりました。例えば、最後の引数を[-5,5]とすると・・・

となりました。度数分布の部分と図➋を比べると、‐5が2個、‐4は5個となっているので階級数が20のまま、集計範囲が-5~4の10個の範囲に絞られているのが分かります。グラフを描画しても・・・
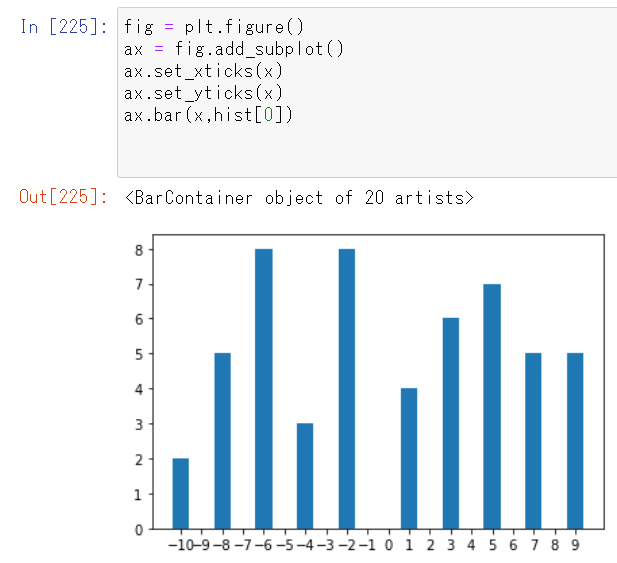
binsは20のままなので、メモリはー10~9まで20個ありますが、集計されている要素(棒の数)は10個です。
とある教材でこの書き方が何の説明もなしに書かれていたのです。
調べてみると分かりますが、殆どのサイトにはnumpy.histogramを書く際には、引数にbinsとして階級数を与えたり、rangeで範囲を与えたりするよう書かれています。
ちなみに、僕は少額とはいえ有料会員として利用しています。
結構プログラミングの学習教材でありがちなのが、こういう細かいけど「?」という部分を何の解説もなしにシレっと入れ込んできたりするんですよね。
知らない人からすると、本筋と関係ないその部分で「?」となってしまいます。今でこそ、ふざけんなという気持ちとともに、調べたりあれこれ実験して、極力一個一個消化していってますが・・・
初心者の頃は、本当にこういう部分がキツかった・・・。(今でも初心者みたいなもんですが)
是非、「この部分は、なんでこう書いているのか」を丁寧に解説するようにして欲しいです。(仮に質問受付可能だったとしても、質問が出ない方が運営側としてもやりやすくないですか!?)
確かに、勉強する側としては、自分で調べたり検証したりすることは、ものすごく勉強になりますし、身につく速度にも影響すると思います。
が、それを言い訳に手を抜くのは言語道断です。お金をもらっている以上、顧客に甘えるのはどうかと思ったので、ここに自分の学習のメモとやり切れない気持ちを封印する次第です。笑
1人がサポートしています
10.00 ALIS













