 454.56 ALIS
454.56 ALIS  124.82 ALIS
124.82 ALIS 
こんばんは、ちょっと更新が空いてしまいました。仕事がちょっと立て込んでるノンストップ飯田です。
今日は、Google CloudのAPI※を利用して、音声ファイルの言葉をテキストに起こすということをPythonでやってみたいと思います。
※アプリケーションプログラミングインターフェースといって、外部のプログラムから機能を呼び出して利用するサービス。今回は、Googleの音声をテキスト化するAIプログラムをPythonで書いたプログラムから呼び出して、利用させてもらうということです。

本記事の構成⁼手順は以下の通りです。
1.Google Cloud platformを利用できるようにする
2.利用したいAPIサービスを探して有効化する
3.認証情報を作成しAPIキーを取得する
4.必要なライブラリをpip インストールする
5.Pythonでプログラムを書く
6. 音声ファイルを用意する
7. 実行する
では、始めましょう。
この記事が分かりやすいので、参照してください。(いきなりサボり)
正直、僕は何も読まずに凸りましたが、何とかなりました。クレジットカード番号も入力しますが、無料クレジットがもらえるので、60日間は無料で利用できます。
1の手順で登録をすると、コンソールが開けるようになります。↓

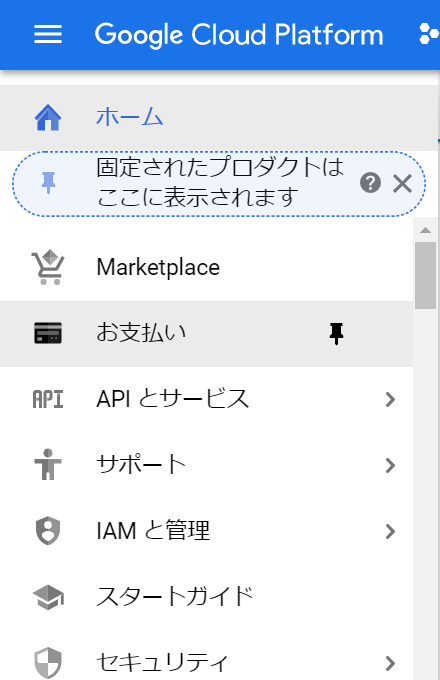
ホームの下にある、メニューの中から「APIとサービス」を選んでください。
検索バーでSpeech APIと検索をすると、3個対象が出てきますが、Cloud 「Speech-to-Text API」を選びます。
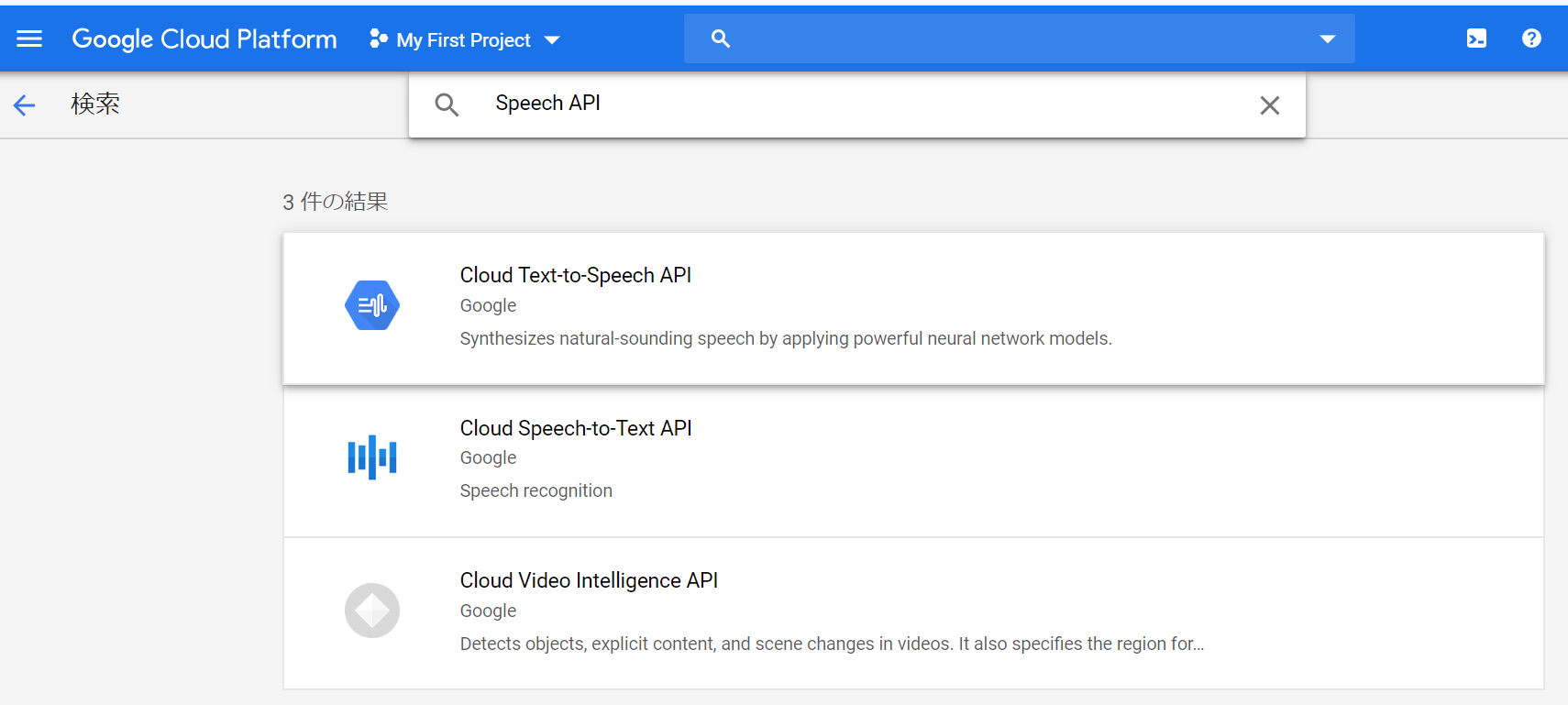
選んだら、有効化しましょう。
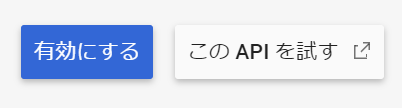
次に、APIを利用するためのAPIキーを取得します。これはGoogleのAIプログラムを、利用させてもらうための認証キーです。
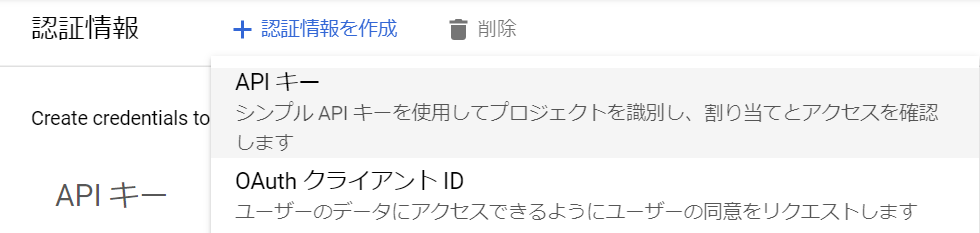
APIとサービスの「認証情報」を選択します。
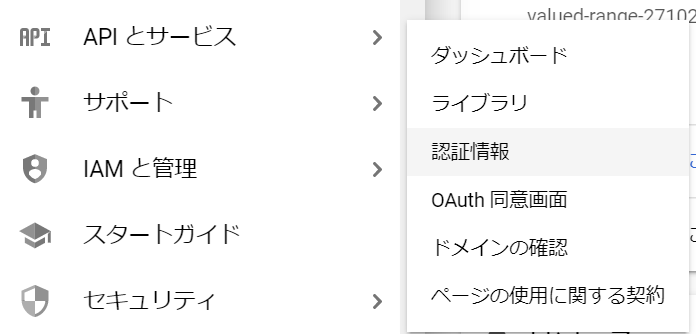
「+認証情報を作成」から「APIキー」を選ぶと、API Keyを選択すると発行されます。
次に必要なライブラリをpip installします。
以下の公式ページにも記載はありますが、pip installでgoogle-api-python-clientをインストールします。(ハイフンが間に入るので注意)
では、次はコードを書いていきましょう。
ざっと説明すると・・・
➀ 冒頭で必要なモジュールをimportしています。
~import base64
以下の部分。with openというファイルを読み書きするコードで、path_フォルダにあるfile変数に格納した音声ファイルを開いて、base64.b64encodeでASCII文字列に変換して、speech変数に格納しています。

~from googleapiclient import discovery
これがSpeech APIを利用するためのライブラリで、事前にpip installしたものです。
以下の部分で、get_speech_service()をservise変数に格納したうえで、.speech().recognize()でAPIを呼び出しています。
ちなみに、recognizeの引数としてbodyという辞書の中に、更にconfigとaudioとありますが、configは音声ファイルの形式を表しています。
flacというファイル形式で、RateHertsが44100(周波数44,100Hzのことです)で、languageCodeはja-JP(日本語)だよとお伝えしてます。APIで連携する時に、定めれた連携項目名で情報をお伝えしているんだなーくらいでいいです。
audioは音声ファイルを渡しています。contentとして、先ほどbase64を使ってエンコードしてspeech変数に格納したものを、今度はUTF-8という文字コードで復元して渡しています。

つまり、Googleさんの「音声ファイルをテキスト変換するAIプログラム」の力を借りるために、必要な情報をJSONという辞書形式で渡すとともに、解析結果をもらっている訳です。
解析結果はservice_requestという変数に格納されています。
最後に、responseという変数に結果を保存したうえで、for関数で一個ずつテキストを取り出して、ファイルに書き込んでいます。
#SpeechAPIによる認識結果を保存
response = service_request.execute()
#結果を保存したいファイルに書き込む処理
with open('path_ + 保存時のファイル名','a',encoding='utf-8') as f:
for i in response["results"]:
for word in i["alternatives"]:
f.write(word["transcript"])6.音声ファイルを用意する
コードが書けたら試してみたいとこだと思いますが、そもそもflacファイルなんかないし、レートとかどうやって設定すんのさ?そんな都合のいい音声ファイルないわよ。とさぞかしお怒りの方もいらっしゃると思います。
他にも方法があるかもしれないので、あくまでも参考ですが、僕はこうやってます。
例として、YOUTUBEから音声ファイルを拾ってきて、config通りの設定に変換するという流れを書きます。
僕の敬愛する、大好きなトム次郎さんという方の「ロバと農夫」という、動画を使ってみたいと思います。
上記のアドレスを、offlibertyというサイトで、MP3ファイルに変換します。

上の欄にURLを入れると、OFFとなっているボタンが電源マークに変わるのでクリックします。
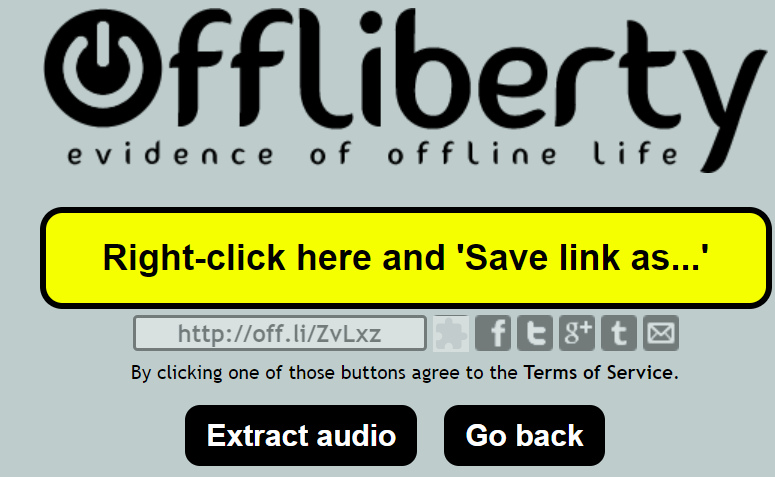
こんな画面が出てきたら、更にExtract audioファイルを選択します。
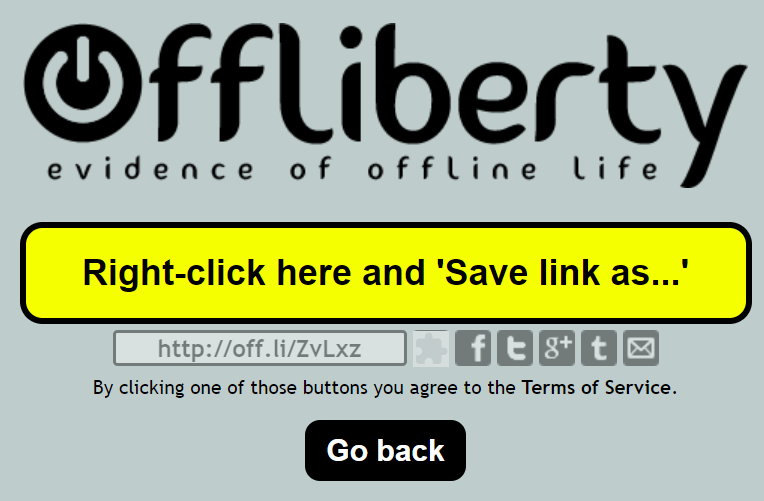
再度こんな画面が表示されましたら、黄色い欄にあるURLをクリックすると、動画から分離されたAudioファイルがダウンロードされます。
mp3ファイルが用意できたら、以下のサイトでconfigに合わせた設定に変換します。

左にある、Audio converterの中にあるConvert To FLACを選びます。
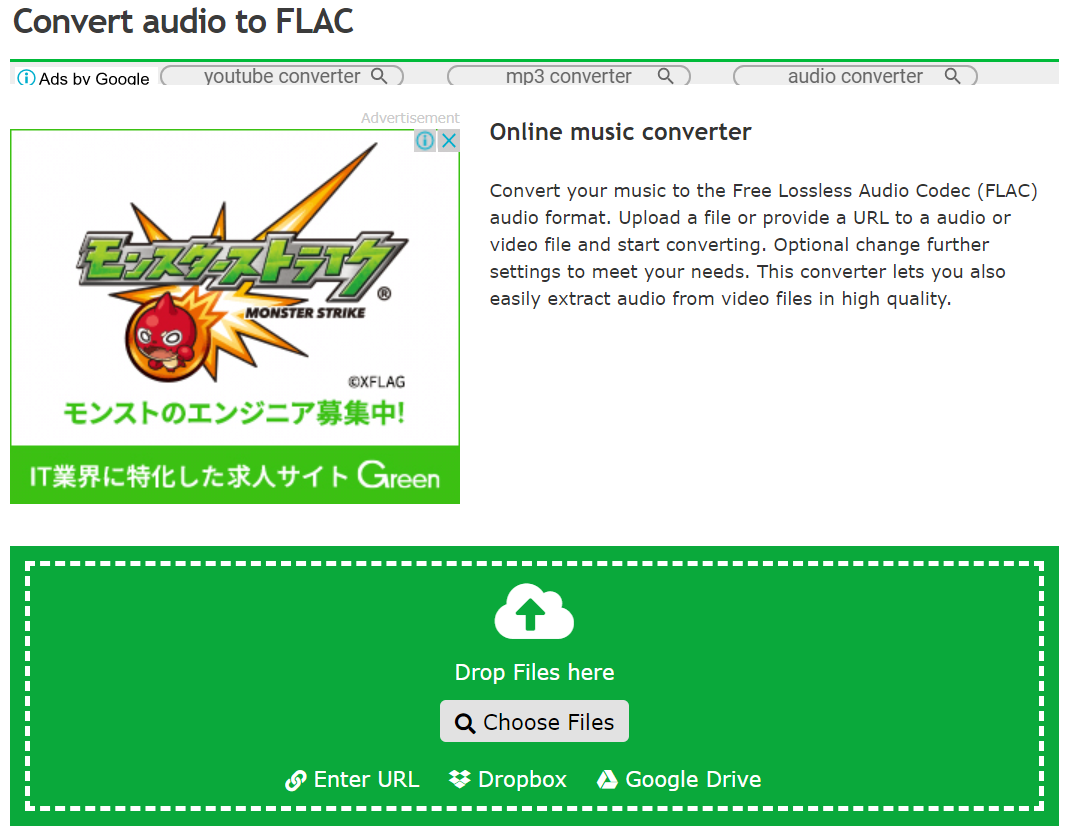
以下の設定をします。ちなみに、噛み噛みなスタートから51秒目までが特に題材として面白そうなので、トリミングも一緒にします。
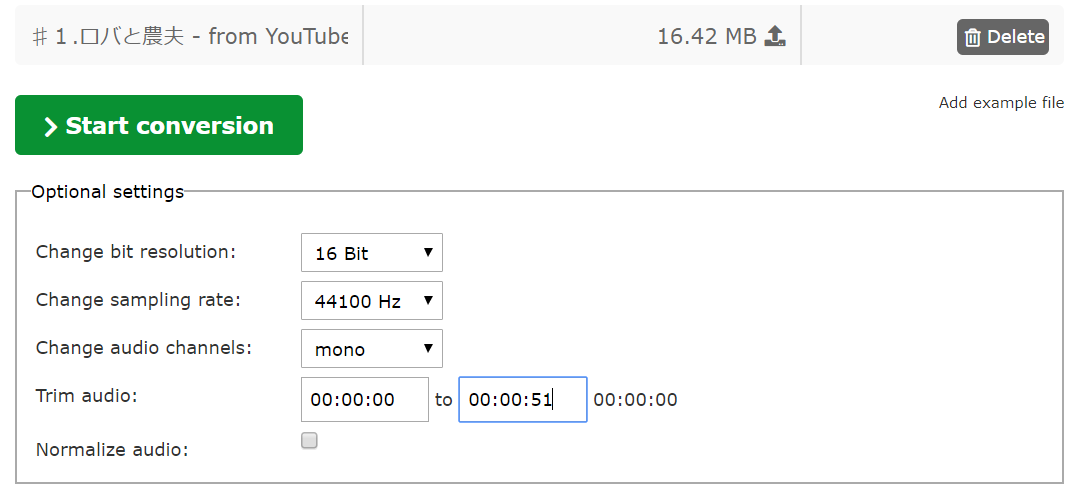
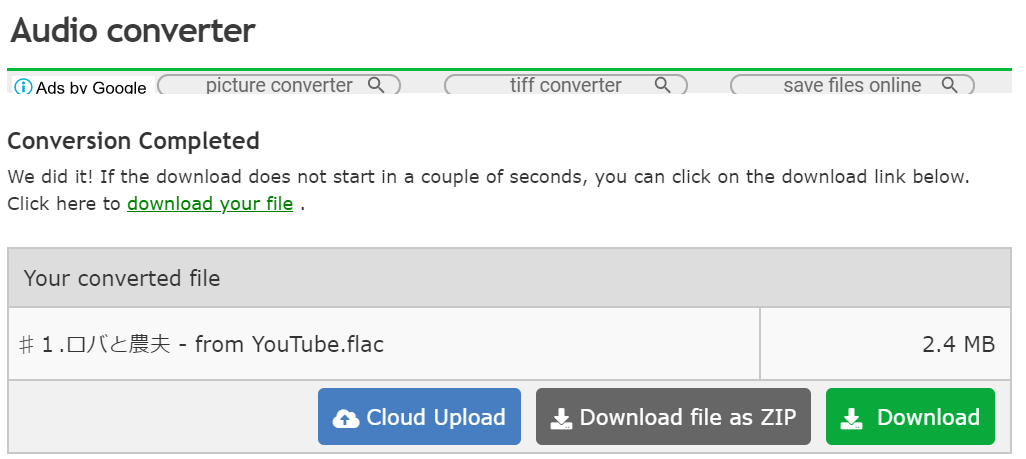
処理が完了したら、緑色のDownloadボタンでファイルをダウンロードします。
後は、プログラムで指定しているフォルダ(path_)にファイルをおいて、ファイル名を英数字に変換し、そのファイル名をプログラムのファイル名のところに書いてください。
では、先ほどのプログラムを実行してみましょう!!

僕は保存するファイル名を"result_convert.csv"としていたのですが、ファイルが作成されています。
中身をテキストで見てみると・・・

さあ(笑)
是非動画も見て、見比べてみてください。
但し、文字からもうかがえる通り多分動画が面白過ぎて、何やってたか忘れてしまう可能性大なので注意してください。
トム次郎さん、復帰お待ちしてます。。。
最後まで読んでいただいて、ありがとうございました!また、時間があるときに他のAPIも試してみたいと思います。
2人がサポートしています
3.34 ALIS














