 454.56 ALIS
454.56 ALIS  124.82 ALIS
124.82 ALIS 
おはようございます。
今日は、実際に僕がPythonista(iPhoneやiPadでPythonが実行できるアプリ)でほぼ毎日のように起動しているWebスクレイピングのコードをご紹介します。
※Pythonistaなんぞや?という方は以下を参照ください

実行内容は、@マークITというアイティメディア株式会社が運営する、IT系の情報サイトから、記事のタイトルとリンクを抽出するものです。
実際にサイトを訪れて、読みたい記事を選べばいーじゃん?そうなんです。
しかし、iPhoneで画面をスクロールしながら、広告以外の読みたい記事を探して・・・って意外に面倒で。あ、僕かなりの面倒くさがり屋なんです。
実はPythonistaで実行すると、コンソールに表示されたリンク(URL)から直接記事に飛ぶことができるため、すごく便利なのです。
↓こんな
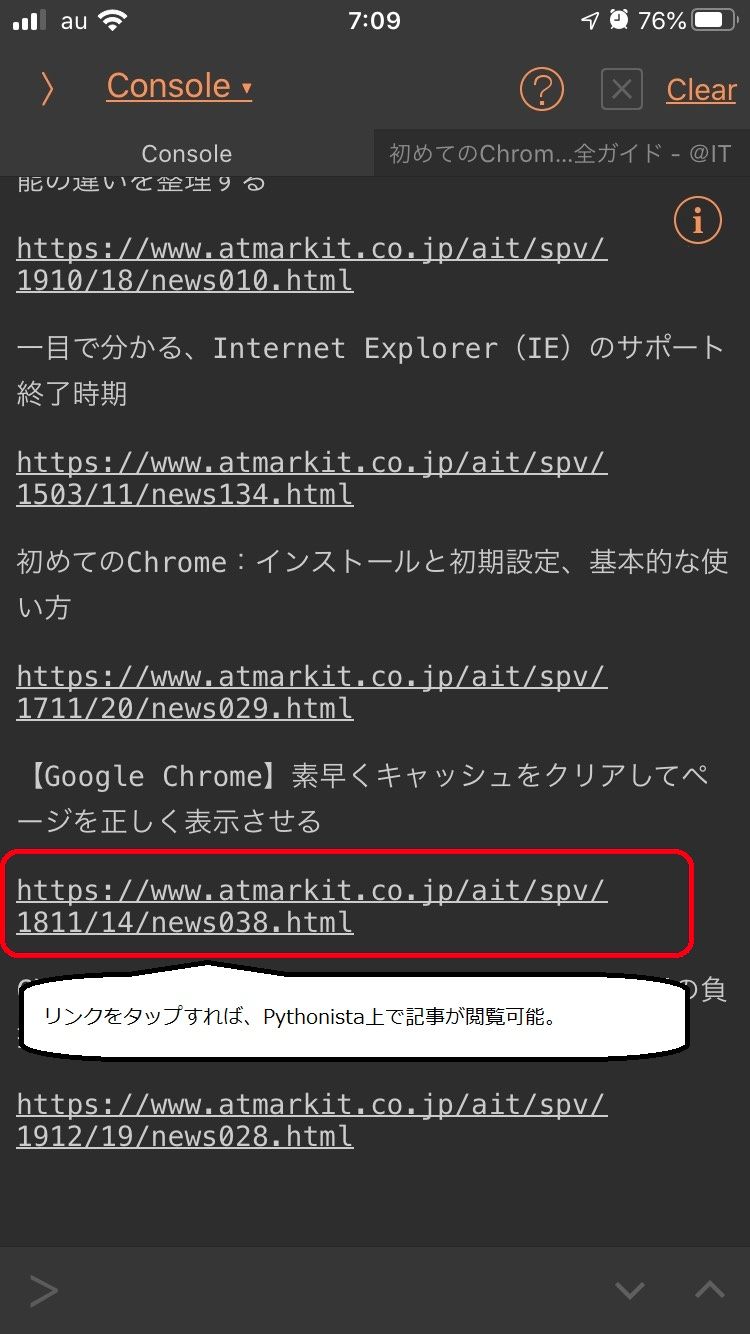
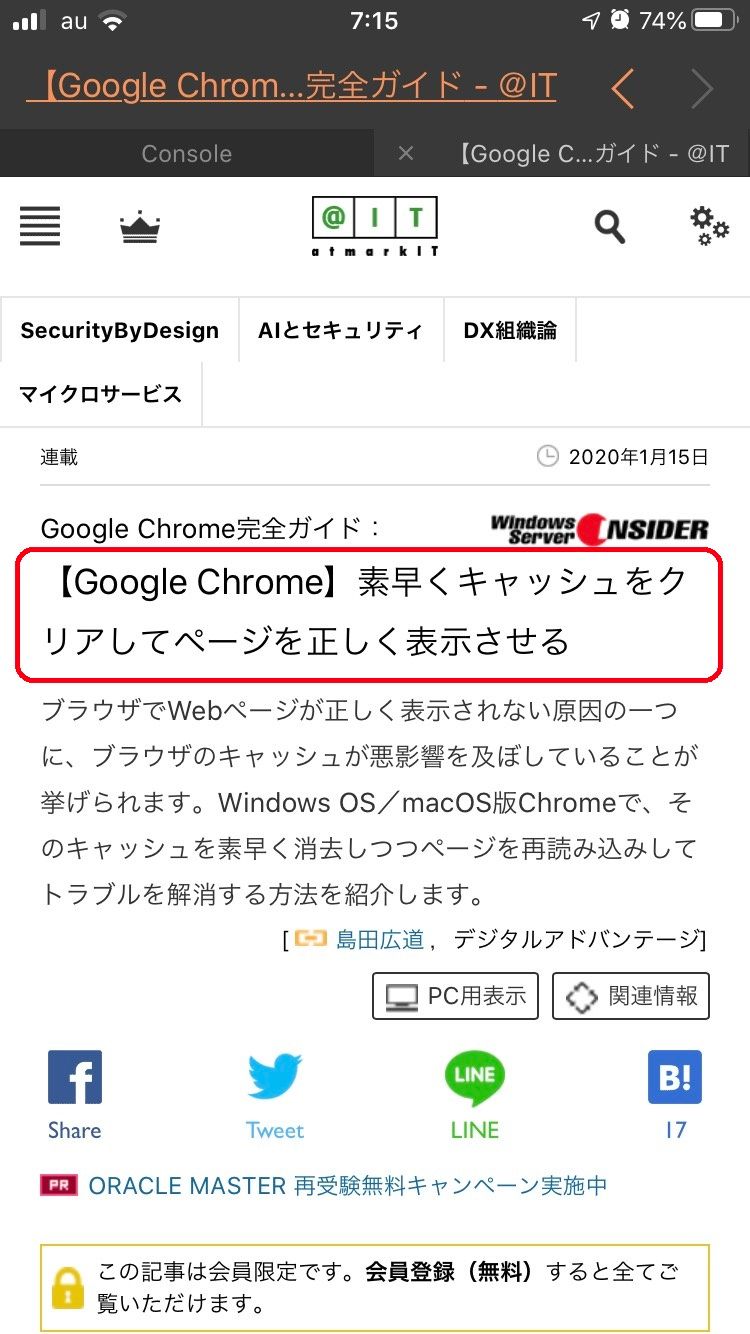
Pythonista内でそのまま記事が読めるのが、すごく便利なのです。
唯一難点は、上の画面にもあるとおり記事によっては会員限定です。(登録は無料)
都度ログインしないといけないのが面倒。そこで僕は、➀タイトルを見て気になった記事だけ開く、➁もっと先まで読みたいという記事はリンクをコピーして、chromeで開きなおして全文読む、➂更に後で見返しそうだなという記事はEvernoteに連携。
ということを毎朝やってます。新聞読んで、ITニュース読んで、時間余ったらPythonistaでなんかコード書く。というルーティンが多いです。
結構、Python関連の記事も多いから、そのままPythonistaでコード試してみたりなんてことも多いです!
スクレイピングする時に使うと便利な、BeautifulSoupはPCだと外部モジュールとしてpip installしないと使えませんが、Pythonistaはなんと標準装備しています!
ある訳ないと思って、初めから諦めていたのですが、よく見たらありました(笑)
ざっくりどんな処理をしているかというと、
目に入るものをできるだけ少なくするために、前回までに実行した際に表示・保存した記事はカットするためです。
urlという変数に@ITのURLを渡して、リクエスト送信(requests.get(url))をしてページのHTMLコードを取得します。(14行目~16行目)
取得したレスポンスをWEBサイト側が利用している文字コードでエンコードして、テキスト形式にします。(17・18行目)
BeautifulSoupにテキスト形式にしたレスポンス情報と、HTML言語のテキスト解釈をするためのhtml.parserを引数として渡して、変数soupに格納。soup.find_all('a')というスクレイピング処理でaタグを抽出。タイトルとリンク(URL)をリストに格納します。(20行目~30行目)
ちなみに、GoogleCromeで右クリック→検証とすると、HTMLコードが確認できます。どのように、スクレイピングしていけば欲しい情報だけ取れるか、確認が可能です。
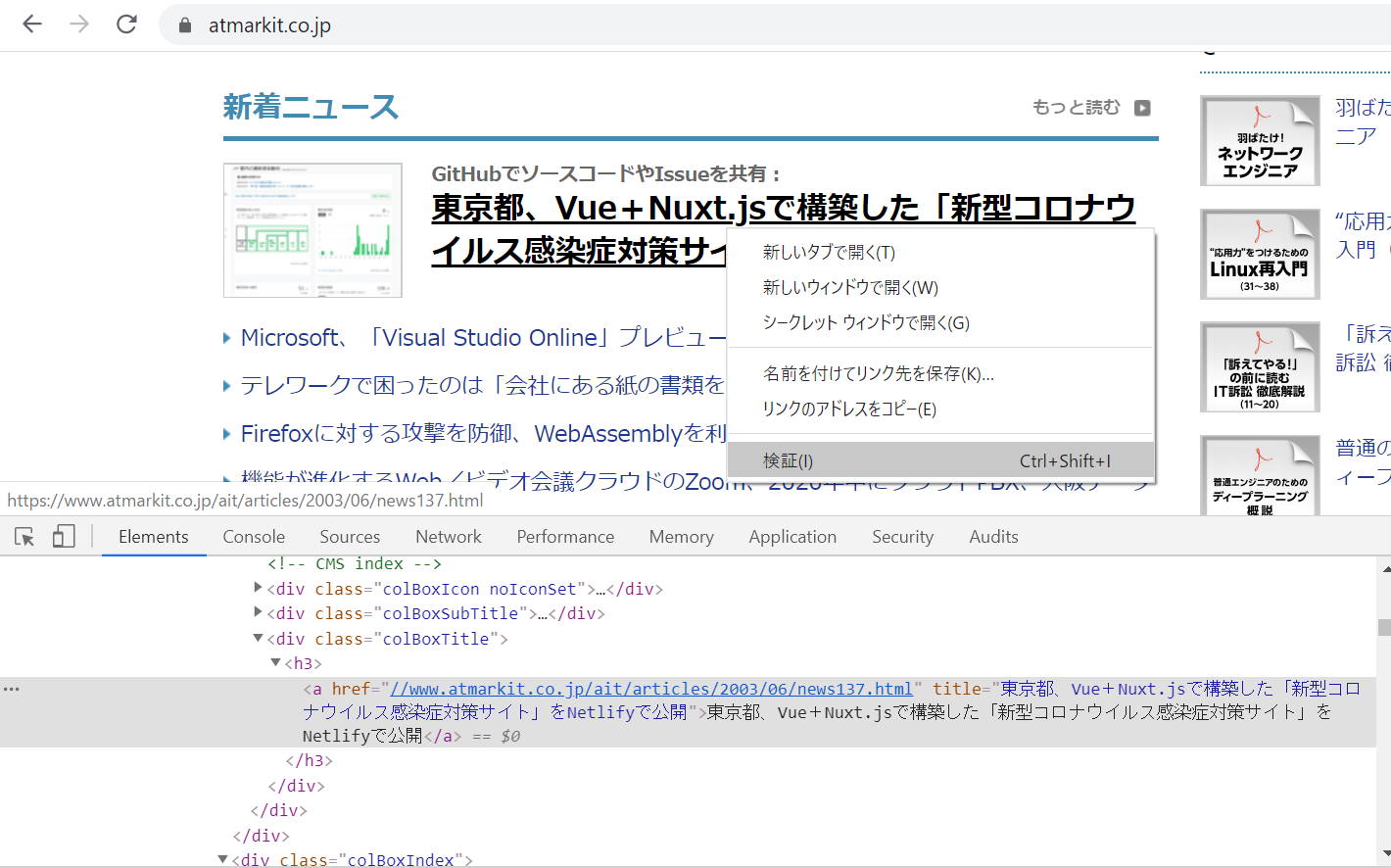
この場合は、aタグ(<a href="・・・・・”>✕✕✕✕</a>)の記事タイトルをもあるので、text属性で記事タイトル、href属性でURLが取得できます。
find_all()はリスト形式で、aタグの情報を抽出するので、リストから順番に取り出して、.textでテキスト情報を取り出して、titlesというリストに記事タイトルを、['href']でhref以降のURLをlinksというリストに放り込んでます。
※.strip()は余計な空白がついている場合に、削除するためのものです
※https:が頭についていない場合、リンクから飛んでもWEBサイトが参照できないため、httpsがあるかを確認して、無い場合は足したうえでリストに放り込んでます。
※WEBサイト内に同じ記事が複数回登場することもあるので、41・42行目で記事タイトル、リンク(URL)それぞれのリストで重複をなくす処理をしています。
いつ処理をしたのか?何件記事を収集して、何件は重複のため捨てたのか?収集結果を後で見返す、または次回プログラム実行時に記事の重複を探すための源泉にするため、CSVファイルに書き込む処理です。
最後まで読んでいただき、ありがとうございました!
1人がサポートしています
1.10 ALIS













