 287.65 ALIS
287.65 ALIS  28.42 ALIS
28.42 ALIS 
最近は時代なのか、特にインターネットを利用する場合に、英語の文章を読む機会が多くなりましたね。私は、もうそういうお年ごろではないのですが、高校以来の英語学習をこのごろ頑張っております🦀
あまり能力はないのですが、以下のもの時々やっております🐂
◎ ラジオ・エンジョイ・シンプル・イングリッシュ(NHK出版)
慣れないことをする場合、モチベーションを維持するのは大変ですよね。よくできた時に褒めてくれたり、駄目なときは優しく叱ってくれる素晴らしい教師がいればいいのですが、年をとってしまうと、精神的にも社会的にも💰金銭的💰にも?なかなか難しくなります🍘
以前、日本語音声合成アプリとして、Open-JTalkというのをダウンロードしていたのですが、付属でついてくるMeiちゃん👸に、なにかこう励ましをいただけたらなあ…と妄想し、pythonでキクタンを使用して英単語トレーニングのプログラムを組んでみました🍄
◎ 音声デモはこちら
※ ライブラリがMMDなので初音ミクみたいなこともできるみたいですが、ちょっとやってみたところ、寄生獣というアニメでいうミギー状態になったのでやめました🎃
およその実質の学習期間が2ヶ月弱で、あるていど結果が分かってきましたので、簡単なアルゴリズムと結果発表をしようと思います。コードについては、ほぼほぼ思いつきで入れてった、いわゆる🍝スパゲッティ🍝なので、申し訳程度で後半にあげます。プレミアムですが、おまけもあるよ🎉
※ 英語トレーニングのコード部分までがトークン不要で読めますが、おまけも面白くなるように頑張ったので読んでいってね🎎
全体構成をまず考えないといけないのですが、自分だけが使う前提なのでビルドやテストなど構成管理はやりません(当たり前ですが何か😅)が、Open-JTalk、データ集合、表示・処理するプログラムは必要になりそうです🎲
Open-JTalkのダウンロード等については、ルート管理が関わってきて面倒なので割愛します(ggrksという私がカスですごめんなさい🙇🙇💦💦)
データ集合については、表計算ソフトから作成できるCSVを使用することにします。データ項目は、
・ en:英単語
・ jp:日本語訳
・ scoreEtoJ:英単語から意味を正解した得点
・ scoreJtoE:日本語から英語をあてた得点
としました🏈
プログラムはpythonを利用して、上記Open-JTalkを扱う方法についてはksggr💦の成果により、コマンドライン経由でできました。その他利用したモジュールは、
・ pandas:データベースの取扱い
・ random:乱数の発生
・ time:得点を決める場合の時間の取得
・ subprocess:コマンドライン処理
となりました。表示系は諦めました、コマンドラインベースです🎽
全体の流れとしましては、
1. モジュールのインポート、データのロード
2. jtalk()の定義
3. セイ・ハロー🙋
4. 問題例とする英単語を、条件にしたがって4つ選ぶ
5. 4つの中から解答とすべき単語を選ぶ
6. コマンドラインに問題を表示し、入力待ちにする
7. 正誤判定を行い、条件にしたがって得点をつける
8. メイちゃん様👸より「お褒めの言葉💖」「お叱りの言葉💣」をいただく
9. 5〜9を計20回繰り返す。
10. データを登録する
11. セイ・グッバイ🌇、そして…🌌
としました、番号がついているとおり単純なシーケンス型です。何度か、メイちゃんにご登場いただけないときがあるのですが、スピード感を重要視したために、コマンドライン処理を切り分ける方法に単一化したことによるものです。この中のメイちゃんには待っていただけないのです💃
条件がキモとなるのですが、
・ 選択する単語のスコアが、1未満の乱数を3乗して10000を掛けたものに3000を加えた数、より小さくとなるよう選択を繰り返す(乱数は毎回変更する)
・ 正解とすべき単語のスコアは事前に8割に減らしておく
・ 正解した場合は、基礎点として800点を、追加点として2400点を秒単位の回答時間で除したものを、正解した単語のスコアに加える(上限は12000点)
・ 間違えた場合は、正解とすべき単語のスコアはそのまま、さらに選択した単語に対してもスコアを8割に減らす
というようにしてみました。目的は、覚えてない単語を中心に出題するけど、時々よくできているのも出題するよ、という感じです🎰
ここ最近の一週間の実績です。表示でclearance, clearance2となっているのは修正前のscoreEtoJ, scoreJtoEです🎢
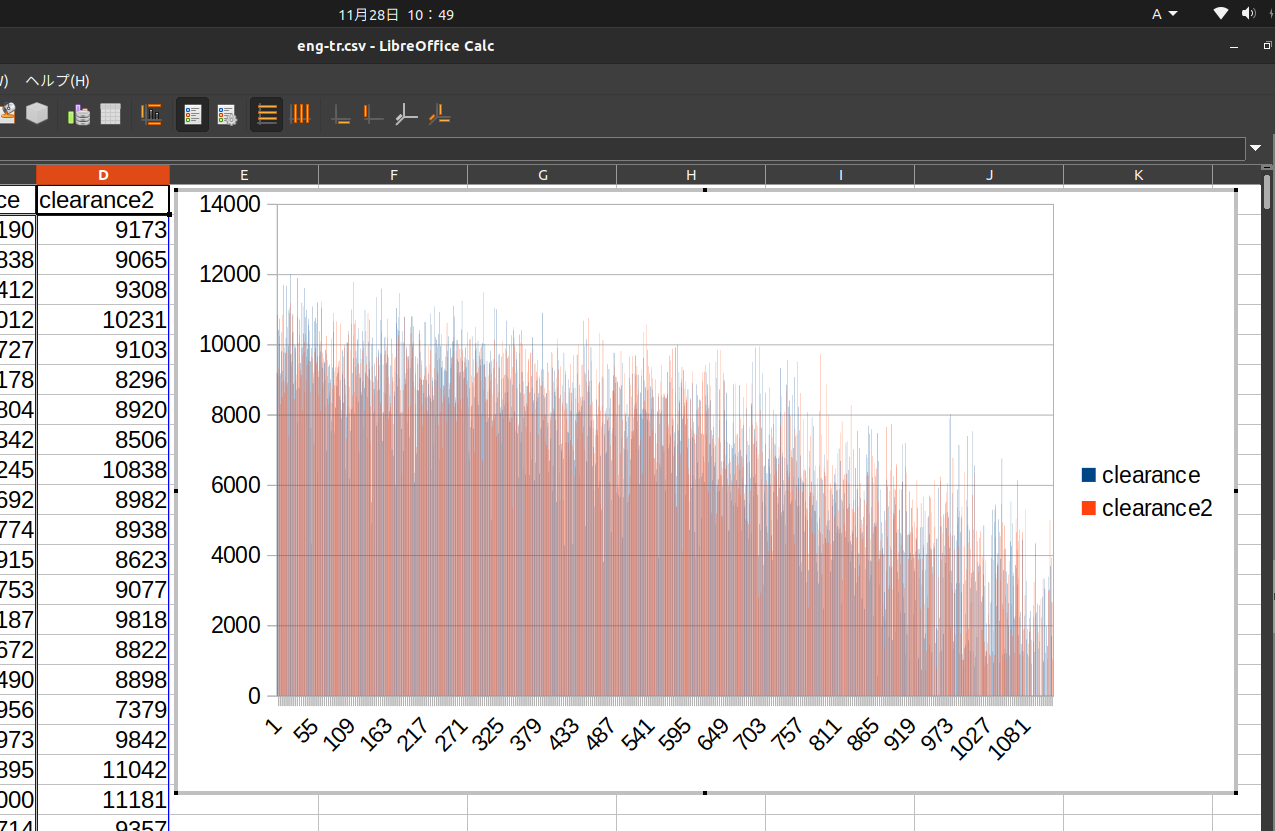
スコアの低い部分にご注目ください🚥
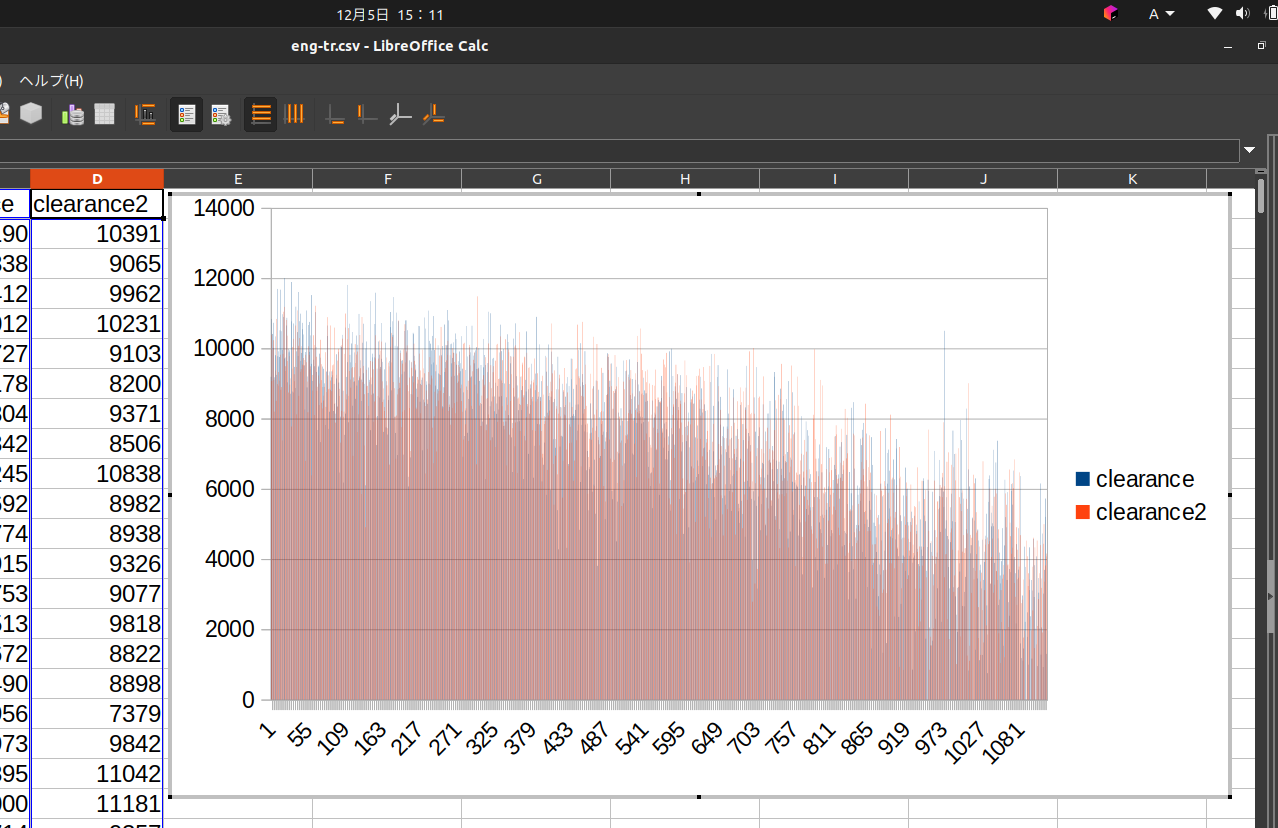
得点の高い部分がときどきドロップする以外さして変更がなく、得点の低い部分が全体的に伸びている感じが分かると思います。実際やっていて「鍛えられてる」という感じは強かったです🔧
残念な点や苦労した点などを少し🚬
メイちゃん様👸は私と同じで英語ができない(別の人で英語ができるのもあるみたいですが…)ので、英語の発音等はそのときには分からないです。キクタンなのでそこからダウンロード編集とか、ウェブ等から取得もできそうですが、さすがにちょっとまずそうな気もします💦
あと、python系は依存関係について良くも悪くもフレンドリーなので、構成ファイルが別途では不要なものの、venvにしてみたり、再インストールしたり、ルートファイルをいじってみたりが大変でした。そういう理由で、anacondaやDjangoみたいなパッケージが必要になるんでしょうね📻
そして、純粋にアルゴリズムが強烈でした。ほんと脳みそから煙や脳汁が出てるんじゃないか、と思うくらいに…絶対に正解できない場合も、残念ながらできてしまっているのですが、まあ良しとしましょう⭐
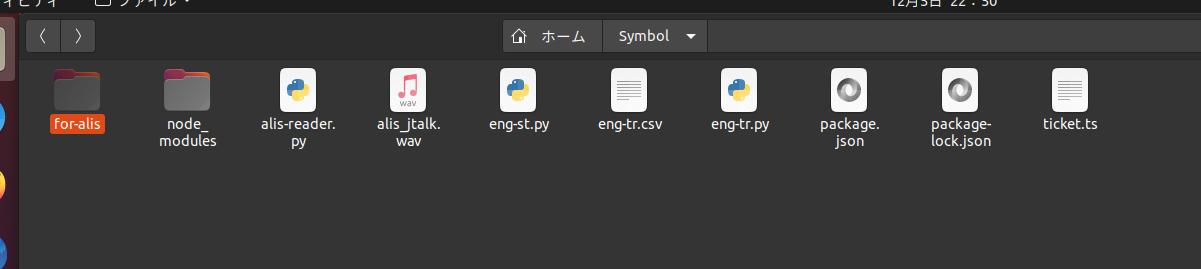
Open-JTalkは、公式のダウンロードどおりにすればルート依存のアドレスに設定されていると思います。eng-tr.pyとeng-tr.csvは同じ階層に置いて下さい。また、プログラムを走らせると、alis-jtalk.wavという音声ファイルが同階層に作成されます。したがって、以下のファイルが同一フォルダ内に存在することになります🍓
・ eng-tr.py
・ eng-tr.csv
・ alis-jtalk.wav
図にある他のファイルやフォルダは、プレミアム部分のちょい見せです🍥
・ eng-tr.csv の作成状況です(CSVで保存して下さい)
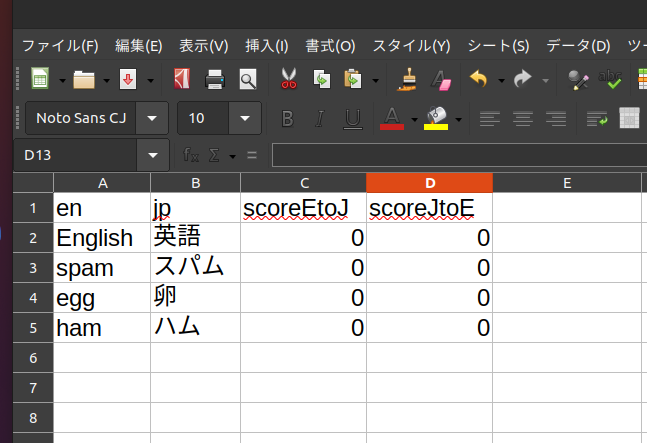
python設計者も、モチベーションを保つ工夫があったことが伺えますね🌋
・ eng-tr.py です🌉
import pandas
import random
import time
import subprocess
data = pandas.read_csv('eng-tr.csv', encoding='utf_8')
def jtalk(t):
open_jtalk = ['open_jtalk']
mech = ['-x', '/var/lib/mecab/dic/open-jtalk/naist-jdic']
# select htsvoice( mei( normal, happy, bashful, sad, angry),
# takumi(normal, happy, sad, angry), slt())
htsvoice = ['-m', '/usr/share/hts-voice/mei/mei_normal.htsvoice']
speed = ['-r', '1.4']
outwav = ['-ow', 'alis_jtalk.wav']
halftone = ['-fm', '0.0']
vpu = ['-u', '0.5']
cmd = open_jtalk + mech + htsvoice + speed + halftone + vpu + outwav
c = subprocess.Popen(cmd, stdin=subprocess.PIPE)
c.stdin.write(t.encode())
c.stdin.close()
c.wait()
aplay = ['aplay', '-q', 'alis_jtalk.wav']
wr = subprocess.Popen(aplay)
jtalk('ハロー')
l = len(data)
today_score = 0
for k in range(20):
print('')
test_n = []
test_word = []
test_mean = []
i = 0
while i < 4:
r = int(random.random()*l)
f = 0
for j in range(i):
if test_n[j] == r:
f = 1
comp_c = int(data['scoreEtoJ'][r])
comp_r = int((random.random()**3)*10000 + 3000)
# print(data['word'][r], comp_c, comp_r, (f==0), (comp_c < comp_r)) # for test
if f == 0 and (comp_c < comp_r):
test_n.append(r)
i += 1
for i in range(4):
test_word.append(data['en'][test_n[i]])
test_mean.append(data['jp'][test_n[i]])
test_r = int(random.random()*4)
test_s = int(int(data['scoreEtoJ'][test_n[test_r]]) * 0.8)
print('""" ', test_word[test_r], ' """')
print('0:', test_mean[0])
print('1:', test_mean[1])
print('2:', test_mean[2])
print('3:', test_mean[3])
old_time = time.time()
ans = input()
if test_r == int(ans):
today_score += 5
print('正解!!!')
test_s = test_s + 800 + int(2400.0 / (time.time() - old_time))
if test_s > 12000:
test_s = 12000
test_s = int(test_s)
data.loc[test_n[test_r], 'scoreEtoJ'] = str(test_s)
print('score: ', test_s / 100, 'point')
r = int(random.random()*4)
if r == 0:
jtalk('正解')
elif r == 1:
jtalk('よし')
elif r == 2:
jtalk('オッケー')
else:
jtalk('いいじゃん')
else:
jtalk('残念。正解は、' + test_mean[test_r] + 'だよ。')
print('......残念!正解は...「', test_mean[test_r], '」')
data.loc[test_n[test_r], 'scoreEtoJ'] = str(test_s)
print('Q score: ', test_s / 100, 'point')
test_s = int(int(data['scoreEtoJ'][test_n[int(ans)]]) * 0.8)
data.loc[test_n[int(ans)], 'scoreEtoJ'] = str(test_s)
print('A score: ', test_s / 100, 'point')
data.to_csv('eng-tr.csv', encoding='utf_8', index=False)
if today_score >= 85:
add_msg = "やったね。"
elif today_score >= 70:
add_msg = "いいじゃん。"
elif today_score >= 55:
add_msg = "もうちょっとだよ。"
else:
add_msg = "ざんねん!もっとがんばろ。"
msg = "メイちゃん: 今回の得点は" + str(today_score) + "点だよ。" + add_msg
print(msg)
print('おつかれさま')
モチベーション低下が問題になる場合は、「お褒めの言葉」を…
r = int(random.random()*4)
if r == 0:
jtalk('ばか!')
elif r == 1:
jtalk('いやん!')
elif r == 2:
jtalk('エッチ!')
else:
jtalk('変態!')などとすれば、良いように思います💗💗💗
間違えた場合の報酬を大きくすると、負の学習効果が低減されますが、辛抱強い性格に矯正される効果は期待できるかもしれませんね💝
なお、既存のデータに登録済みのものがあるかどうかを探すのが面倒なときは、
import pandas
data = pandas.read_csv('eng-tr.csv', encoding='utf_8')
l = len(data)
times = 4
print('入力モード(' + str(times) + '語分)')
print('')
for i in range(4):
t = 0
en =''
while t == 0:
print(i+1, '番目')
en = input('英単語は?')
print(en)
t = 1
for j in range(l):
if data['en'][j] == en:
print('その単語はもうあるよ。')
t = 0
jp = input('意味は?')
data.loc[l+i+1, 'en'] = en
data.loc[l+i+1, 'jp'] = jp
data.loc[l+i+1, 'scoreEtoJ'] = '0'
data.loc[l+i+1, 'scoreJtoE'] = '0'
print('「' + jp + '」だね。オッケー!')
print('')
data.to_csv('eng-tr.csv', encoding='utf_8', index=False)
print('登録したよ')のようにすればいいでしょう(eng-st.pyとしました)🎠
0人がサポートしています
0.00 ALIS














