 822.04 ALIS
822.04 ALIS  139.19 ALIS
139.19 ALIS 

リンク:
アリスブログ > 「ALISのAPI」を使用する方法まとめ > 当記事
◆ 【Python】「ALIS Media」の「HTMLデータ」を取得してみよう!
「Pythonのインストール」が完了したら、早速、「ALISのAPI」をいじって何か凄いことしちゃおう! と思いたくなるものですよね。
○ 「ALIS」の新着記事を「3件」表示するプログラムのソースコード
import urllib.request
import json
import pprint
cm_data1 = urllib.request.urlopen('https://alis.to/api/articles/recent?limit=3')
article_box1 = json.loads(cm_data1.read().decode("utf-8"))
pprint.pprint(article_box1['Items'])
input('Enterキーで終了')
この文を使用すれば、「ALISのAPI」を利用して、ALISのデータを表示することができます。楽勝です。
……しかしながら、これ、行数こそ少ないものの、結構色々なことを行っていたりします。
無論、「関数化」してしまい、中身をブラックボックスにしてしまっても、特に問題はなかったりするのですが……この記事では、「ALISのAPI」を表示するプログラムの中身を、もう少し詳しく説明していきたいので、
ここでは、プログラムの一部に書かれている、
・urllib.request.urlopen
・read
・decode("utf-8")
が何なのかを記述していきます。
○ 留意事項
・pythonの経験は殆どないので、内容の一部に誤りがあるかもしれません
※ 「2018/09/08」において、記事の一部に誤りがあったので、内容を修正しています。
○ 関連記事
◆ 「ALIS Media」のHTML文を表示する方法
「urllib.request.urlopen」「read」「decode("utf-8")」の3つを使用した例としてわかりやすいのが、他のサイトの「HTMLファイル」を取得するプログラムでしょうか。
そのため、今回は、「ALIS Media」の「HTML」を表示することができるプログラムのソースコードを掲示してみます。
○ 基本型
import urllib.request
url_name1 = 'https://alismedia.jp/ja/'
cm_data1 = urllib.request.urlopen(url_name1)
byte_data1 = cm_data1.read()
html1 = byte_data1.decode("utf-8")
print(html1)
input('Enterキーで終了')
○ 省略型
import urllib.request
cm_data1 = urllib.request.urlopen('https://alismedia.jp/ja/')
print(cm_data1.read().decode("utf-8"))
input('Enterキーで終了')
「基本型」と「省略型」のどちらであっても、ソースコードを実行すると、(インターネットに繋がっていれば、)ALIS公式サイトのデータを取得することができます。
○ 説明
import urllib.request
「urllib.request」という名前のモジュール(便利なプログラム、ライブラリのようなもの)を使用できるようにします。
(もし、この宣言を行わずに他の場所で「urllib.request」と書くと、エラーが発生します)
url_name1 = 'https://alismedia.jp/ja/'
「url_name1」という名前の「変数(自由な型)」を作成した後、「文字列(str型、Stringの省略名)」にして、「https://alismedia.jp/ja/」という文字の情報を保存しておきます。
(「変数 = ''」と書くと、その「変数」は、「文字を保存する型」に変化します)
cm_data1 = urllib.request.urlopen(url_name1)
難所(説明する側にとっても……苦笑)。
urllib.request.urlopen(「文字列」)は、冒頭で読み込んだ「urllib.request」の機能の1つである「urlopen」を使用するものであり、
文字列に書かれているURLのサイトに接続して、サーバーにある情報を獲得できるようにするもの……だったと思います。
それと、ここで「cm_data1」という名前の「変数」に返されるものは、「コンテキストマネージャとして機能するオブジェクト」であり、「cm_data1」には「オブジェクト(クラス)」が詰まっているはずです(多分)。
(※1 なお、この時点で「url_name1」に書かれているURLが存在しないものだと、エラーが発生します)
(※2 「cm_data1」の型を「type()」で確認すると、「'http.client.HTTPResponse'の型」であることがわかります)
・コンテキストマネージャとは
説明が面倒なので省略(というか、よく知らない)。「python コンテキストマネージャ」と「python クラス」で検索してみて下さい。
とりあえず、生成したコンテキストマネージャの(クラスの)内部にある関数が使えるようになると思っておけば、問題ないと思います。
(例:「cm_data1.read()」。「read()」が使用できるようになっている)
byte_data1 = cm_data1.read()
「urllib.request.urlopen」で生成したオブジェクトから「read()」を呼び出すと、指定のURLのサイトから「HTML文」を「bytes型」で取ってきます。
そして、「変数 = 」と記述することで、獲得した「bytes型のデータ」を「bytes型になった『byte_data1』」に入れます。
(※1 read()は、リクエストしたサイトが何も指定してなかったら、HTML文をbytes型で獲得するだけであり、ALISのAPIのURLのように、JSON形式の文字列をbytes型で受け取るケースもあります)
(※2 本来、「read()」は「close()」とセットで使うものなのですが、このような短いプログラムの場合は、アプリが終了した後に「close()」が呼ばれるので、「close()」を省略することができます)
html1 = byte_data1.decode("utf-8")
既に、指定のURLのサイトから取ってきた「HTML文」を「byte_data1」に詰め込んであるので、後はそれを表示すれば良さそう……に思えるのですが、
「byte_data1」に保存されているのは「bytes型」であり、そのまま表示すると「日本語」が表示されません。
なので、ここで「uft-8」と呼ばれる「都合の良い文字コード」に変換して(「str型」にして)、日本語の表示ができるようにしておきます。
print(html1)
獲得したHTMLの情報を、コマンドプロンプト上に表示(可視化)です!
成功すると、こんな感じになります。
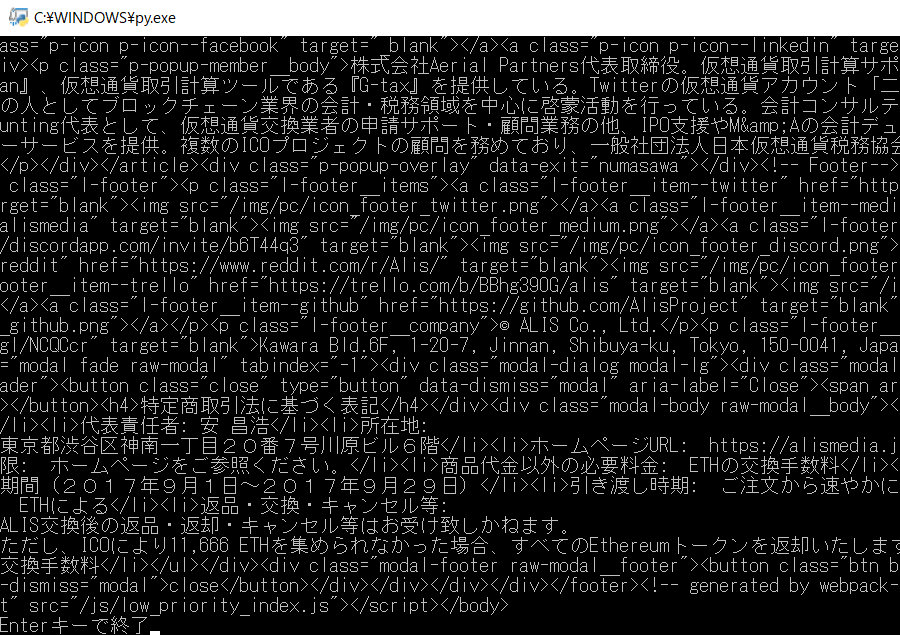
ALISの運営サイトに書かれていることが、HTML形式で表示されていますね。
input('Enterキーで終了')
いつもの「おまじない」。
……実は、inputは、Enterキーで終了するものではなく、何らかの文字の入力待ち状態するだけであり、Enterキーを押せば先に進むようになります。
まぁ、結果として、Enterキーで次に進んで終了になるわけですけど……。
どうです?
この記事で、「urllib.request.urlopen」「read」「decode("utf-8")」の用法がわかりましたかね?
……これらの文は、冒頭の「ALISのAPIを利用するソースコード」にも書かれているので、HTMLを表示するソースコードと比較しながら、どのような仕組みであるのかを理解してみるのが良いと思います。
◆ 「ゆうき」のツイッター















