822.04 ALIS
822.04 ALIS  139.19 ALIS
139.19 ALIS 

リンク:
アリスブログ > 「ALISのAPI」を使用する方法まとめ > 当記事
◆ 【Python】特定のALISユーザーの「記事の情報」を全部取得してみよう!
「ALISの記事を『1000件』読み込めるプログラムの説明」の続き(応用)。
記事を大量に呼び出す技術は、ユーザーの記事を呼び出すAPIにも流用できるので、試してみました。
○ 関連記事
○ 留意事項
・「2018/09/11」に作成した記事です
・ALISのAPIの仕様が変わると、このプログラムは動作しなくなる可能性があります
◆ 「指定されたユーザーの公開記事一覧情報を取得」を行うAPIの仕様について
前からよく使用していた「/articles/recent」のAPIとの大きな違いは、「page」というパラメータがないことでしょうか。
これにより、ページの指定によるoffset(スキップ)ができなくなっています。
ですが、代わりに「article_id」と「sort_key」が用意されており、
これに「特定の文字列」を代入すると、「『article_id』と『sort_key』の値が一致する記事」が対象となった上で、記事の読み込みを行う場所が、「対象となった記事」より「1つ先の記事」に設定されます。
例えば、私(「yuuki」というユーザーID)の現在の「新着記事の番号」を順番に取得した場合は、
→ スタート地点
Num1: KBXep8VnE6A9
Num2: 2xABQELVp1oJ
Num3: aw5zQQwJxzMy
Num4: 3Njo5mWkDA5M
Num5: 39rBEq9W711y
になるのですが、
ここで、「Num2: 2xABQELVp1oJ」の記事から「article_id」と「sort_key」の情報を入手した後、それらの値を「/users/{user_id}/articles/public」のパラメーターに設定して呼び出すと、
Num1: KBXep8VnE6A9
Num2: 2xABQELVp1oJ
→ スタート地点
Num3: aw5zQQwJxzMy
Num4: 3Njo5mWkDA5M
Num5: 39rBEq9W711y
に変化します。
これにより、pageのパラメータがなくても、offsetを再現することが可能です。
・「article_id」と「sort_key」は、どのような時に用いるのか
記事を101件以上投稿しているユーザーから、101件以上の情報を取得したい場合に用います。
「/users/{user_id}/articles/public」のAPIにおいても、limitの限界は「100」に設定されているので、1度の呼び出しで、101件以上の記事の情報をすることは、できません。
そのため、101件以上の記事を取得したい場合は
A,X回目の呼び出しを行う(X >= 2)
B,X回目の呼び出し場所は、(X-1)回目において読み込みが終わった場所を指定しなければならない
という点が必要となることから、
「B」の条件を満たすために、offsetの再現が行える「article_id」と「sort_key」を使用します。
◆ 特定のユーザーの記事の情報を「limit1 × loop_num」個、取得するプログラム
import urllib.request
import json
import pprint
import time
#任意の値
user_name1 = 'yuuki'
limit1 = 3
loop_num = 3
#固定の値
article_id_memo1 = ''
sort_key_memo1 = ''
#page1 = 1 # 特に使用していないので、コメント化
article_box2 = []
for count1 in range(loop_num):
try:
url_name1 = f'https://alis.to/api/users/{user_name1}/articles/public?limit={limit1}'
if count1 >= 1:
url_name1 += f'&article_id={article_id_memo1}&sort_key={sort_key_memo1}'
cm_data1 = urllib.request.urlopen(url_name1)
article_box1 = json.loads(cm_data1.read().decode("utf-8"))
article_box2.extend(article_box1['Items'])
load_article1_len1 = len(article_box1['Items'])
#page1 += 1
print("Load : " + str(count1))
if load_article1_len1 <= 0:
break
else:
article_id_memo1 = article_box1['Items'][load_article1_len1 - 1]['article_id']
sort_key_memo1 = article_box1['Items'][load_article1_len1 - 1]['sort_key']
#time.sleep(1)
except:
print("Error!")
break
print("")
for article3 in article_box2:
print("article_id : " + article3['article_id'])
print("title : " + article3['title'])
print("")
print("要素数 : " + str(len(article_box2)))
input('Enterキーで終了')
※ 追加(修正)した部分は、太字にしています
○ 追加した部分の説明
user_name1 = 'yuuki'
user_idを文字列で定義。
ここでは、私のALISの記事が対象になっていますが、「yuuki」の文字を別の人の「ユーザーID」に変更すれば、その人の記事の情報が得られます。
article_id_memo1 = ''
sort_key_memo1 = ''
上記の「APIの仕様」の件から、2回目以降の呼び出しには「article_id」と「sort_key」が必要となるため、保存できる変数を用意しておきます。
url_name1 = f'https://alis.to/api/users/{user_name1}/articles/public?limit={limit1}'
URLの設定です。
前回まで、
url_name1 = 'https://alis.to/api/users/' + user_name1 + '/articles/public?limit=' + str(limit1)
のような形式で記述していたのですが、
前回の記事で、「がくしさん」から以下のようなコメントを頂けたので、
pythonのバージョンが3.6なら、f文字列が使えますよ。
頭にfを付けると、文字列の{}内に変数を入れられます。
こう書いてたのが、
'https://alis.to/api/articles/recent?limit=' + str(limit1) + '&page=' + str(page1)'
こう書けます。
f'https://alis.to/api/articles/recent?limit={limit1}&page={page1}'
f文字列(フォーマット文字列)を使って、スマートな形式にしてみました。
if count1 >= 1:
url_name1 += f'&article_id={article_id_memo1}&sort_key={sort_key_memo1}'
ループ回数が2回目以降の時は、「article_id」と「sort_key」に、
「(X-1)回目」に読み込んだ「『記事の集合』の中の、一番最後の記事」に書かれていた「article_id」と「sort_key」が必要となるので、
それを追加で代入できるようにしておきます。
一例:
1回目の呼び出し:
url_name1 = 'https://alis.to/api/users/yuuki/articles/public?limit=3'
2回目以降の呼び出し:
url_name1 = 'https://alis.to/api/users/yuuki/articles/public?limit=3&article_id=XXXXXXXXXXXX&sort_key={XXXXXXXXXXXXXXXX'
「url_name1」の後ろに、「article_id」と「sort_key」の文字列が増えています。
load_article1_len1 = len(article_box1['Items'])
一度の読み込みで読み込んだ記事の個数を、変数に保存しておきます。
・おまけ
……上記の文の後に、
print("len1 = " + str(load_article1_len1))
という「『load_article1_len1』の値が確認できるコード」を記載しておけば、プログラムの動作の仕組みがわかりやすくなるかもしれません。
if load_article1_len1 <= 0:
break
読み込めた記事の個数が「0個」だったら、ループから抜けます。
(このプログラムを実行した場合、読み込める記事の個数は「limit」の値分だけ減っていきます)
else:
article_id_memo1 = article_box1['Items'][load_article1_len1 - 1]['article_id']
sort_key_memo1 = article_box1['Items'][load_article1_len1 - 1]['sort_key']
読み込めた記事が「1個」以上だったら(記事が存在していたら)、一度に読み込んだ「複数の記事」の中の「一番最後の記事」から、「 article_id」と「sort_key」を獲得して、保存用の変数に代入します。
print("title : " + article3['title'])
今回は、記事のタイトル名も表示してみました。
○ 実行結果
「limit1 = 100」「loop_num = 3」で実行。
(最大で「300記事」取得します)
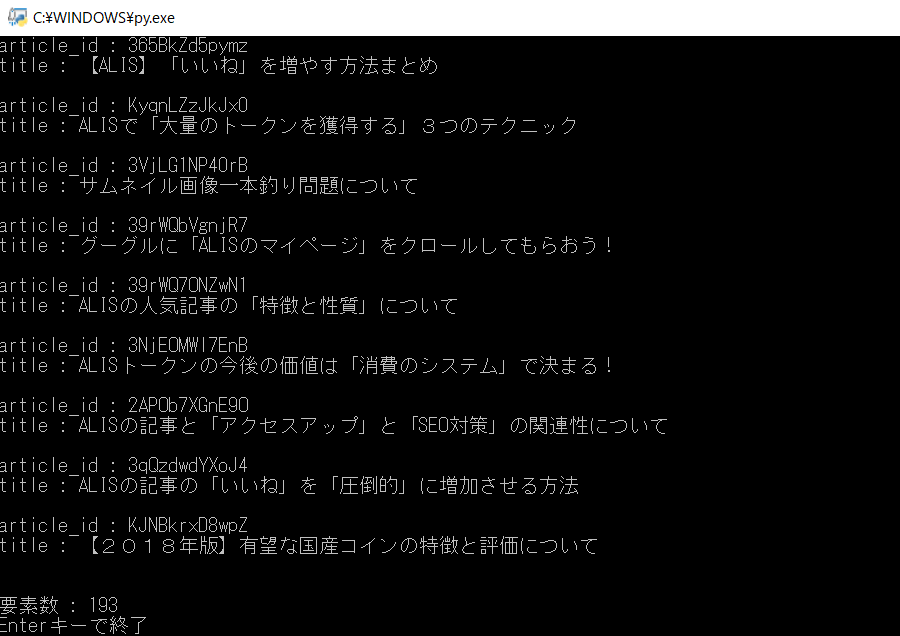
一番最後の記事まで、全部取得することができました。
◆ 「ゆうき」のツイッター