289.96 ALIS
289.96 ALIS  244.00 ALIS
244.00 ALIS 
The Graph
The Graphの各コンテンツをフォローしてご参加ください!

この記事は、The Graphのコア開発者Semiotic LabsのSam GreenとTomasz Kornutaによって提供されました。
2021年12月、SemioticはThe Graphの4番目のコア開発者チームとなりました。私たちはThe Graphに人工知能(AI)と暗号機能の融合をもたらすための研究に重点を置いていますが、プロトコルへの貢献に関しては、応用とインパクトを重視する考え方を持っています。私たちは、専門的なDevOpsスキルを必要とするThe Graph Network上のインデクサーを運用することでこれを実現し、2021年初頭からsemiotic-indexer.ethを運営しています。さらに、私たちはAIの専門知識を駆使して、2つの自動化ソフトウェアツールをThe Graphのエコシステムにリリースしました。AutoAgoraとAllocation Optimizerです。
この記事では、私たちのAIへの取り組みの概要を説明し、The Graphのユニークなデータインデックス機能をAIアプリケーションに活用する方法についての将来のアイデアを概説します。
The Graphは、ブロックチェーンのデータをインデックス化し、ダップフロントエンド、プロット、ダッシュボード、またはデータ分析などの下流アプリケーションで使用するためのクエリに利用できるようにするための分散型プロトコルです。The GraphにおけるAIのユースケースは数多く存在します。The GraphにおけるこれまでのAIのユースケースは、自動化意思決定のためのツールの配備でした。また、The Graphがインデックス化した豊富なWeb3データにアクセスするための参入障壁を下げることも、新たなAIのユースケースとして考えられます。ここでは、主に前者のユースケース、つまりThe Graphにおける自動化のためのAIの利用に焦点を当てていきます。
The Graphや分散型プロトコルは一般的に、プロトコル参加者が最適かつ正直に行動するよう奨励するためのインセンティブ・メカニズムを使用しています。インセンティブ・メカニズムとは、望ましい行動に対する報酬のことで、行動経済学の概念です。例えば、The Graphでは、消費者はインデクサーにGRTを支払うことで、インデクサーにクエリを提供するインセンティブを与えます。同様の仕組みが、各役割にも存在し、それらは皆、行動を導く特別なインセンティブを持っています。
分散型プロトコルを構築することの意義は、意思決定が中央集権的なエンティティ(例えば企業)から離れ、プロトコルの参加者に向かうということです。The Graphの文脈では、分散化によって、参加者は多くの複雑な意思決定をする必要があります。Semiotic Labsは、AIと関連技術を使用して、プロトコル参加者の意思決定プロセスを簡素化するツールを展開します。私たちは、2つのAI関連ツールの開発に貢献しました。AutoAgoraとAllocation Optimizerです。これらのツールはいずれも、インデクサーのプロトコルのパフォーマンスと収益の向上を支援するものです。
The Graphの目的は、ユーザーにクエリを提供することにあります。プロトコルは複数のインデクサー(データ販売者)、消費者(データ購入者)、およびゲートウェイを含んでいます。顧客が複数のゲートウェイのいずれかにクエリを送信すると、ゲートウェイは、インデクサーの入札価格、サービス品質(QoS)、遅延などの様々な要因に基づいて、インデクサーの間でクエリを分配します。インデクサーは、クエリを提供することで報酬を得るとともに、提供するクエリの価格を自由にコントロールすることができます。このプロセスは以下のように描かれています:

インデクサーは、さまざまな GraphQLクエリに対する入札価格を、Agora というドメイン固有の言語で定義されたモデルの形で表現します。Agoraの価格モデルは、クエリをGRTにおける価格にマッピングします。つまり、与えられたインデクサーがクエリを実行する金額について具体的な価格を提供します。しかし、各サブグラフに対してAgoraモデルを作成・更新するのは面倒で時間のかかる作業であるため、多くのIndexerは代わりに静的でフラットな価格モデルを使用しています。
また、インデクサーの価格設定を支援し、クエリの市場価格に従っていることを確認するために、Semiotic LabsはAutoAgoraというオープンソースのツールを作成しました。AutoAgoraはAgora価格モデルの作成と更新のプロセスを自動化し、Indexerが特定のクエリ形状に対応する実際のコストを反映した動的な価格設定を提供することを容易にします。つまり、AutoAgoraは、The Graph Networkでのクエリサービスをより競争力のある柔軟な価格で提供したいと考えるインデクサーにとって有用なツールなのです。
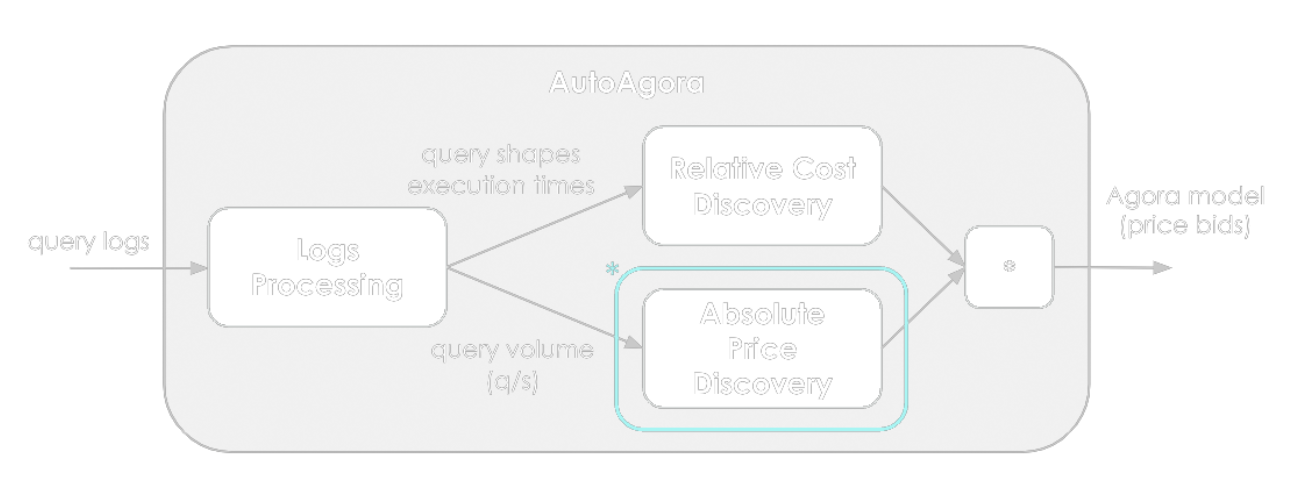
上記のように、AutoAgora は、Agora価格モデルの作成と更新のプロセスを自動化するために連携するいくつかのモジュールで構成されています。これらのモジュールは以下の通りです:
ログ処理:受信したクエリ、形状、実行時間を抽出するためにログを解析する。
相対的なコストの発見:類似したクエリの形状をグループ化し、リソースの使用統計(例:平均実行時間)を計算する。
絶対価格発見:過去に提供したクエリ量に応じて価格を調整し、収益を最大化する。
絶対価格発見モジュールでは、AIを使用しています(上図の青枠)。このモジュールでは、強化学習で使われる学習可能な確率的エージェントの一種であるガウシアン・バンディットを実装しています。クエリの価格設定の文脈では、エージェントのポリシーは、可能なクエリ価格に対するガウス分布として表され、エージェントが取る行動は、このポリシー分布からサンプリングされます。サンプリングされた価格は、Agoraモデルを更新するために使用され、いくつかのゲートウェイのうちの1つに送信されます。全ての技術的な複雑さを除外して(単純化して)、バンディットがそのポリシーを更新するために使用するロジックは次のように説明できます:AutoAgoraを実行しているインデクサーが膨大な量のクエリを提供するなら、価格を上げるべきで、もしクエリがないのなら明らかに価格が高すぎます。
AutoAgoraの一般的な情報については、インフラの詳細を説明した私たちのブログ記事、または2022年6月のGraph Hackでの私たちの講演を参照してください。強化学習とガウシアンバンディットに関するより詳細な情報は、arxivのイエローペーパーと2022年10月のDevCon VIでの講演で発表されています。
現在、The Graph Networkには750以上のサブグラフが配備されています。コンシューマーがサブグラフのクエリーを行う前に、インデクサーはサブグラフに関連するブロックチェーンデータを「同期」し、サブグラフにGRTを割り当てる必要があります。サブグラフを同期させてからクエリを提供するのは非常にリソース集約的なタスクなので、通常、インデクサーはすべてのサブグラフを同期させることはありません。実際には、グラフネットワークは以下の図のようになり、インデクサーは可能な限り多くのサブグラフのうちのいくつかに割り当てられます。
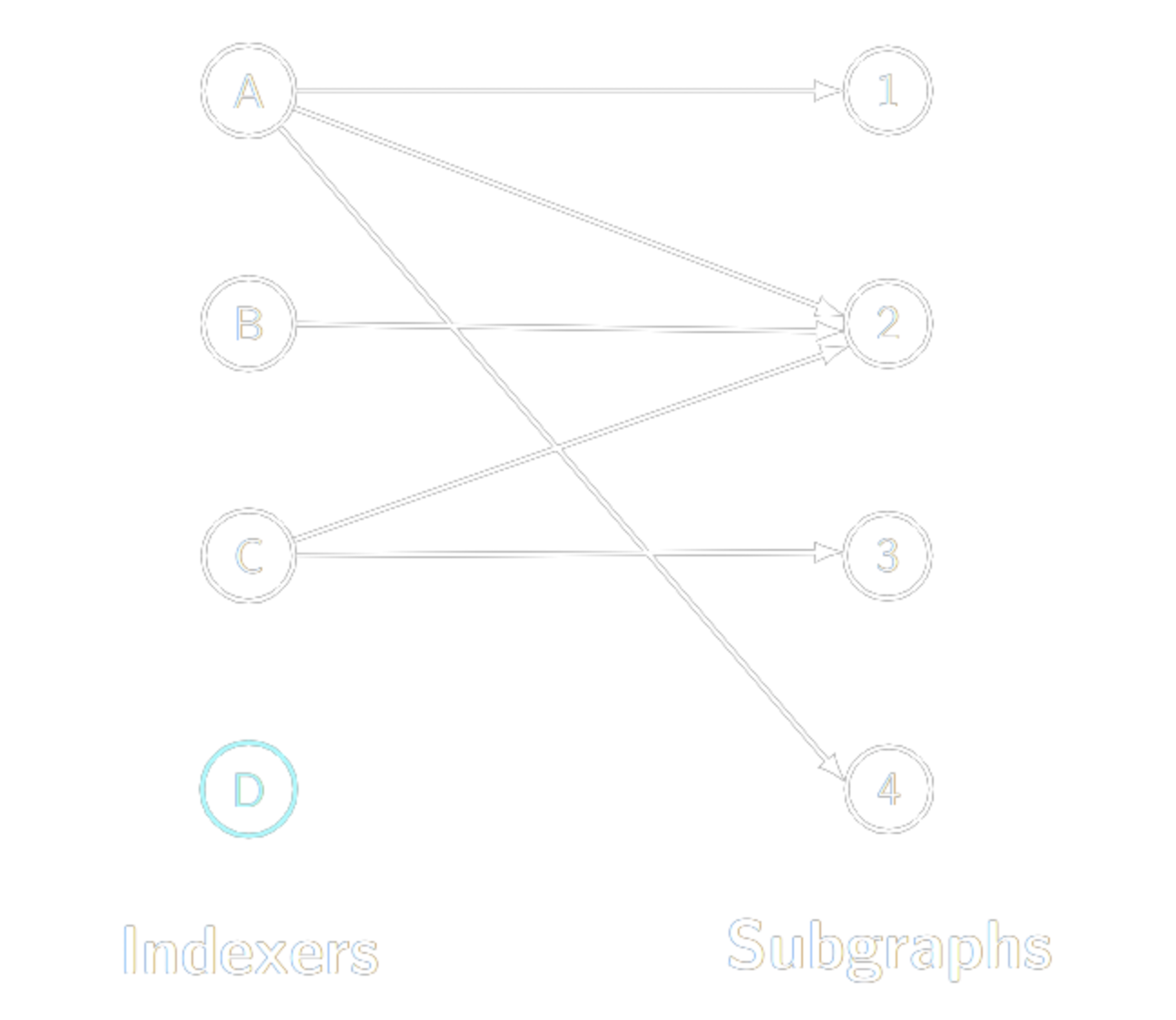
インデクサーはどのようなサブグラフに割り当てるべきかをどのように判断するのでしょうか?それはキュレーターの役割です。キュレーターは、サブグラフのGRTにシグナルを送ります(一時的に預ける)。キュレーターは、特定のサブグラフのクエリ料金が上がれば報酬を得られるので、合理的なキュレーターは、クエリ料金が高いサブグラフにシグナルを送ろうとします。それに応じて、プロトコルは、インデクサーがクエリフィーの高いサブグラフに向かうように誘導し、そのクエリに対応するようにする。シグナルに従うことで、インデクサーはクエリ料金の高いサブグラフに行き着くことになります。しかし、割り当ての問題はそれほど簡単ではありません。全てのインデクサーが最も高いシグナルを持つサブグラフにのみインデックスを付けるとしたら、それはうまくいかないだろう。もしそうであれば、他のサブグラフは提供されないことになります。その結果、インデックス作成報酬は、高シグナルのサブグラフにいるインデックス作成者に報酬を与えますが、他のインデックス作成者がすでに多くのステークを割り当てているサブグラフにいるインデックス作成者にはペナルティを与えることになります。どのサブグラフにインデックスを作成するかを決めるために、インデクサーは、シグナルではなく、インデックス報酬に従わなければなりません。
多くのインデクサーにとって、インデクサー報酬に従うことは非自明なことである。実際、完全な問題はモジュラー関数の最適化であることが判明しており、これは学術的な文献ではまだ解決されていない問題となっています。Allocation Optimizerは、インデックス作成者のためのオープンソースツールであり、少なくともその道の一部を切り開くことができます。このツールは、現在のキュレーションの状態、他のインデクサーの既存の割り当て、特定のインデクサーの利用可能なGRTの量、およびガスコストを入力として受け取ります。そして、このツールは、インデクサーの代わりに最適化問題を解きます。Allocation Optimizerの出力は、インデクサーに対する推奨事項です。この推奨には、どのサブグラフにどれだけの量を割り当てるかが含まれます。
割り当て最適化は難しい数学的問題ですが、数学的問題を解決しても、それだけでプロトコルが改善されるわけではありません。最適な割り当てを計算できるツールをインデクサに提供することで、インデックスの報酬収入を増やし、インデクサの時間を解放して、サブグラフのクエリに対して高品質のサービスを提供することに集中できるようにします。
これまでこの記事では、The Graph Networkで使用するために現在配備されているAI関連ツールに焦点をあててきました。しかし、The Graphは他にどのようにAIを活用できるのでしょうか?また、別の視点から、AIビルダーはどのようにThe Graphを活用できるのでしょうか?
ChatGPTは、AIへのアクセスを民主化するツールであり、AIにとってのiPhoneの瞬間でした。ChatGPTは、一般的にはLarge Language Model(LLM)と呼ばれるもののブランド名です。LLMは、テキストデータの要約や合成に威力を発揮します。また、数値データの処理にも使えますが、LLMに正しく計算させることは、まだ新しい研究分野です。私たちは、LLMを使ってThe Graphの膨大な情報にアクセスし、要約するためのパイロットプロジェクトを開始しました。具体的には、Web3データに興味のある人なら誰でも、自然言語で直感的にアクセスできるようにする予定です。詳しくは、こちらをご覧ください。
AIビルダーは、どのようにThe Graphを活用できるのでしょうか?一つは、The Graphのデータを新しいAIモデルのトレーニングに利用する方法です。ニューラルネットワークのトレーニングには大量のデータが必要だと聞いたことがあるかもしれませんが、まさにそれがThe Graphにあるのです。また、コンピュータサイエンスの知識がある方なら、「garbage in, garbage out」という言葉を聞いたことがあるかもしれませんが、これは「悪い入力は悪い出力をもたらすと予想される」ということを指しています。ChatGPTやGPT-4などのLLMは、インターネット上の多くの公開データ(したがって、偽りや矛盾のあるデータ)で訓練されているため、「garbage in, garbage out」の問題があります。これは、ChatGPTがしばしば間違っている理由の1つです。ザ・グラフのデータは、検証可能であること、つまり正確であることが超能力の一つです。ですから、より信頼できるAIシステムのトレーニングに役立つ正確なデータをたくさん持っているのです。
プロトコルはAIよりもデータのインデックス作成で広く認知されていますが、The Graphはスタック全体でAIを効果的に活用するために必要な多くの属性を持っています。インデクサーのために、Semiotic Labsは、プロトコルの効率とインデクサーの収益の両方を向上させることができる複雑な意思決定を自動化するオープンソースのAIツールを作成しました。The Graphのユーザーに対しては、自然言語クエリを使ってThe Graphの豊富なデータにアクセスできるようにするパイロットプロジェクトを開始しました。そして将来的には、The Graphは新しいAIモデルをトレーニングするための、信頼できる検証可能なデータのソースになるかもしれません。これらのトピックについてもっと聞きたい方は、GRTiQ Podcastの「AI and Crypto」特別エピソードをお聞きください。
Ahmet S. Ozcan:AhmetはSemioticの共同設立者兼CEOです。現職に就く前は、機械知能グループのマネージャーとして、IBM Neural Computer上での最初のアプリケーション開発など、脳から着想を得たAIアルゴリズムの研究とハードウェアアクセラレーションを主導していました。ボストン大学で物理学の博士号を取得し、IBMマスターインベンターとして100件以上の特許を申請しています。コンピュータサイエンス、認知心理学、神経科学、物理学、マイクロエレクトロニクスなど、さまざまな分野の主要な科学雑誌に掲載された50以上の査読付き論文を含む、幅広い研究貢献をしています。
Sam Green:Sam GreenはSemioticの共同設立者であり、研究責任者です。2009年、応用数学の修士号を取得後、組み込みエレクトロニクスのコンサルティング会社に勤務し、リアルタイムアプリケーション用の低レベルマイクロコントローラコードを開発しました。2010年、Sandia National Laboratoriesに入社し、統計学と機械学習を使って暗号ハードウェアの弱点を分析することを専門としています。2015年、SamはSandiaを離れ、カリフォルニア大学サンタバーバラ校で博士号を取得することになりました。彼の学位論文は、Deep LearningとReinforcement Learningを組み合わせ、不確実性の下で(低消費電力や高速など)意思決定を効率的に行うことができるAIエージェントを構築することに焦点を当ててきました。学位取得後、再びサンディアに勤務し、ハードウェアに適したニューラル・アーキテクチャを発見するための研究を追求しました。
Alexis Asseman:AlexisはSemioticの共同設立者であり、リードデベロッパーです。マイクロ・ナノテクノロジーで修士号を取得後、IBM Researchの機械知能部門に入社しました。IBM在籍中は、400個以上のFPGA(高性能再構成可能ハードウェア)を使用して構築されたIBMニューラル・コンピュータの開発リーダーを務めています。ニューラルコンピュータを用いて、大規模な神経進化実験を行いました。また、記憶増強型ニューラルネットワークや、視覚的な質問に答えるための言語モデルに関する研究も行っています。また、オープンソースのディープラーニングライブラリであるMI-Prometheusの構築にも携わりました。
Anirudh Patel:AnirudhはSemioticのシニアリサーチサイエンティストです。スタンフォード大学で信号処理に特化した電気工学の修士号を取得。大学院で医療画像処理に取り組んでいたとき、胸部X線肺炎の分類における深層学習の成功に刺激を受けました。その結果、コンピュータビジョンに軸足を移した。2018年に修士号を取得した後、AnirudhはSandia National Laboratoriesに行き、深層学習の「Subject Matter Expert」として、研究開発プロジェクトに貢献しました。その結果、ディープ強化学習、セマンティックセグメンテーション、オブジェクト検出、組み込みアーキテクチャ上でのディープラーニングアルゴリズムの展開など、ディープラーニングのさまざまな分野にわたるプロジェクトに携わりました。Sandiaでは、研究イニシアチブの実現可能性のスクリーニングテストとしてしばしば活躍し、ディープラーニング技術への関心を高めるためにワークショップやトレーニングを開催しました。Semioticに入社するまでに、Decentralised Multi-Agent Coordinationを専門にしていました。
Tomasz Kornuta:Tomaszは2022年、エンジニアリング担当副社長兼AI担当としてSemiotic Labsに入社しました。Tomaszはロボット工学と制御の博士号を持ち、過去にはロボット制御とコンピュータビジョンを組み合わせた様々な問題に取り組み、ビジュアルサーボ、シーン合成、オブジェクト操作に応用しました。2015年、IBM Researchに入社し、注意と記憶を利用したニューラルネットワーク、視覚的質問応答とビデオ推論のためのマルチモーダル機械学習に関する研究を行った。2019年、TomaszはNVIDIA AI Applicationsチームに参加し、純粋な自然言語処理研究にさらに関わり、自己教師付き学習と大規模言語モデル(LLM)の最新の進歩を活用して、対話管理と意味検索に取り組みました。ロボット工学や制御、コンピュータビジョン、自然言語処理、機械学習など、幅広いテーマで80以上の査読付き論文を執筆し、4件の米国特許を取得しています。また、これらのトピックに特化した数多くのワークショップや特別セッションを開催しています。また、さまざまなジャーナルや会議の査読者としても活躍し、3Dロボットの知覚に特化した特集号も編集した。最後に、DARPAの資金援助による助成金やEUの第7次フレームワーク・プログラムの助成金2つを含む、多くの研究プロジェクトや助成金に参加した。
The Graphは、web3のインデックスとクエリーのレイヤーです。 開発者はサブグラフと呼ばれるオープンAPIを構築・公開し、アプリケーションはGraphQLを使用してクエリを実行することができます。
The Graphは現在、Ethereum, NEAR, Arbitrum, Optimism, Polygon, Avalanche, Celo, Fantom, Moonbeam, IPFS, PoAなど39種類のネットワークからのインデックスデータをサポートしており、さらに多くのネットワークが近日中に登場する予定です。現在までに、74,000以上のサブグラフがホスティングサービス上に展開されています。
グラフネットワークの開発者向けセルフサービス体験を2021年7月にローンチして以来、500以上のサブグラフがネットワークに移行し、180以上のインデクサーがサブグラフのクエリを提供し、9,300以上のデリゲーター、2,400以上のキュレーターが参加しています。現在までに400万GRT以上がシグナルされ、サブグラフあたり平均1万5千GRTとなっています。
Web3アプリケーションを構築している開発者であれば、ブロックチェーンからのデータのインデックシングやクエリにサブグラフを利用することができます。The Graphによって、高い効率性とパフォーマンスによるUIデータ表示が可能になり、他の開発者もあなたのサブグラフを使用することができます。また、Subgraph Studioを使ってネットワークにサブグラフをデプロイしたり、Graph Explorerにある既存サブグラフをクエリすることができます。
The Graph Foundationは、The Graph Networkを統括しており、同時にThe Graph Foundationは、Technical Councilによって統括されています。Edge & Node、StreamingFast、Semiotic Labs、The Guild、Messari、GraphOpsが、The Graphエコシステム内の外部組織として貢献参加しています。
The Graphの各コンテンツをフォローしてご参加ください!
1人がサポートしています
101.00 ALIS