 287.65 ALIS
287.65 ALIS  28.42 ALIS
28.42 ALIS 
(以前の記事)
先日、コラッツ予想でプログラム競争みたいなのをいくつかあげていましたが、アセンブラ系もやってみました。シフト演算のメリットがあるかどうか、ということです。以前、基本情報技術者を受けたときは言語はCASL2&COMET2で受けたので、まずそれでやってみます。
🏢CASL2
結論を先に述べますと、CASL2とは情報技術者試験用のものであって、可読性や追跡可能性の観点から16BIT仕様であったところがネックとなりました。コラッツナンバーのような不確定に増加・減少するような数を扱うには、だいたい倍の情報量が必要ですが、65536までの情報量では800程度までしか扱えず、ここでどうしようかとても悩みました。
まずは、800程度でオーバーフロー:65536以上になるプログラムです。
COLLATZ START
;
RPUSH
LD GR1,DATA1
LAD GR2,1
MAINLP CPL GR2,GR1
JPL MAINFI
ST GR2,DATA2
CALL COLFNC
LAD GR2,1,GR2
JUMP MAINLP
MAINFI LD GR3,CHKSUM
; DREG ='GR3 '
RPOP
RET
;
COLFNC RPUSH
LD GR1,DATA2
LAD GR2,0
COLCHK CPL GR1,=1
JZE COLFIN
LAD GR2,1,GR2
LD GR3,GR1
AND GR3,=1
CPL GR3,=1
JZE COLODD
COLEVN SRL GR1,1
JUMP COLCHK
COLODD LD GR3,GR1
SLL GR1,1
JOV COLERR
ADDL GR1,GR3
JOV COLERR
LAD GR1,1,GR1
JOV COLERR
LAD GR2,1,GR2
SRL GR1,1
JUMP COLCHK
COLERR OUT MSG,MSGLEN
; DREG ='OVERFLOW'
COLFIN LD GR4,CHKSUM
ADDL GR2,GR4
ST GR2,CHKSUM
; DREG ='GR2 '
RPOP
RET
;
DATA1 DC 700
DATA2 DS 1
CHKSUM DC 0
MSG DC 'ERROR'
MSGLEN DC 5
END
シフト演算でコラッツ予想のプログラムはとても相性がいいみたいで、ここで最適化できるかは分かりませんが、そのように動作した場合は、非常に効率的に処理することが予測されます。
そしてオーバーフラグのエラーを補足すると、それを表示するようにしてます。703で初めて発生します。
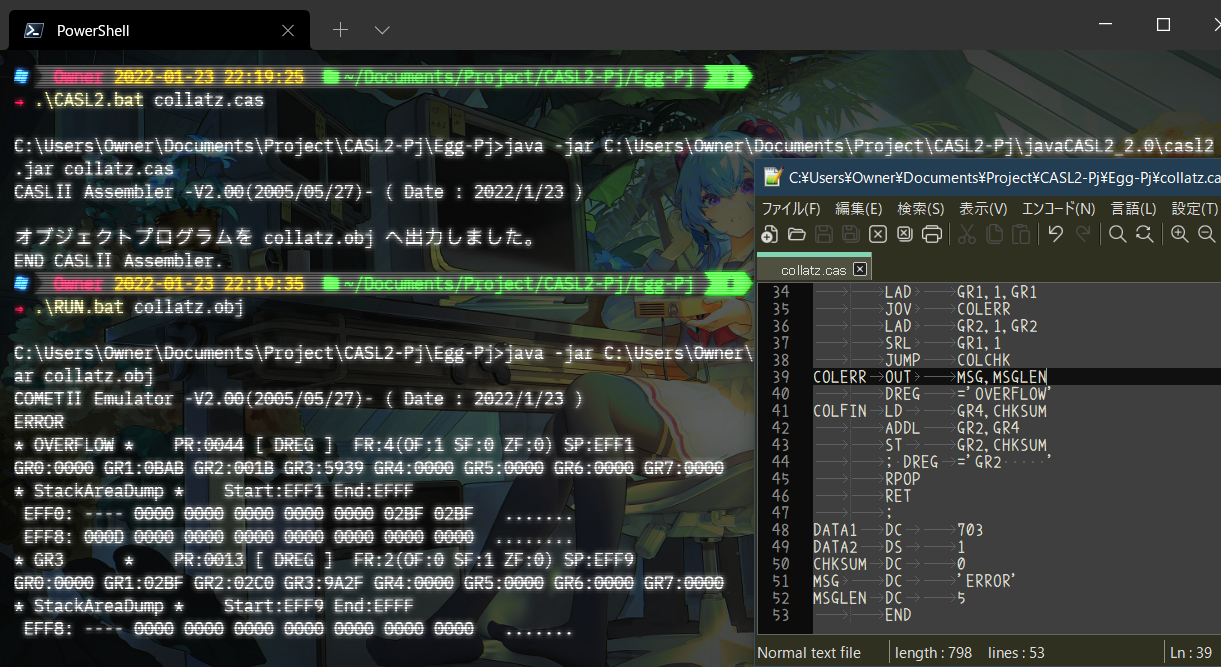
3回分のオーバーフラグの処理があれば、繰り返し用の処理プロセスを作るのですが、計算資源が先に底をつくでしょうから、無理矢理一本化しました。16ビット×3という構成にしました。
COLLATZ START
;
RPUSH
LD GR1,DATAMU
LD GR2,DATAML
LAD GR4,0
LAD GR5,0
MAINLP CPL GR5,GR2
JZE MAIN2
JUMP MAIN3
MAIN2 CPL GR4,GR1
JZE MAINFI
MAIN3 ADDL GR5,=1
JNZ MAIN4
LAD GR4,1,GR4
MAIN4 ST GR4,DATAIM
ST GR5,DATAIL
CALL COLFNC
JUMP MAINLP
MAINFI CPL GR4,GR1
JNZ MAINLP
LD GR1,CHKSUM
DREG ='LAST GR1'
RPOP
RET
;
; === COLLATZ FUNCTION 16BIT*3 ===
COLFNC RPUSH
LD GR1,DATAIL
LD GR2,DATAIM
LAD GR3,0
LAD GR4,0
COLCHK CPL GR1,=1
JNZ COLOPR
CPL GR2,=0
JNZ COLOPR
CPL GR3,=0
JZE COLFIN
COLOPR LAD GR4,1,GR4
LD GR5,GR1
AND GR5,=1
CPL GR5,=1
JZE COLODD
;
COLEVN SRL GR1,1
SRL GR2,1
JOV COLEVN2
JUMP COLEVN3
COLEVN2 LAD GR1,32768,GR1
;OUT MSG,MSGLEN
COLEVN3 SRL GR3,1
JOV COLEVN4
JUMP COLCHK
COLEVN4 LAD GR2,32768,GR2
;OUT MSG,MSGLEN
JUMP COLCHK
;
COLODD LD GR5,GR3
SLL GR3,1
JOV COLERR
ADDL GR3,GR5
JOV COLERR
LD GR5,GR2
SLL GR2,1
JOV COLODD2
JUMP COLODD3
COLODD2 ADDL GR3,=1
JOV COLERR
COLODD3 ADDL GR2,GR5
JOV COLODD4
JUMP COLODD5
COLODD4 ADDL GR3,=1
JOV COLERR
COLODD5 LD GR5,GR1
SLL GR1,1
JOV COLODD6
JUMP COLODD8
COLODD6 ADDL GR2,=1
JOV COLODD7
JUMP COLODD8
COLODD7 ADDL GR3,=1
JOV COLERR
COLODD8 ADDL GR1,GR5
JOV COLODD9
JUMP COLODDB
COLODD9 ADDL GR2,=1
JOV COLODDA
JUMP COLODDB
COLODDA ADDL GR3,=1
JOV COLERR
COLODDB ADDL GR1,=1
JOV COLODDC
JUMP COLODDE
COLODDC LAD GR2,1,GR2
JOV COLODDD
JUMP COLODDE
COLODDD ADDL GR3,=1
JOV COLERR
COLODDE JUMP COLCHK
;
COLERR DREG ='OVERFLOW'
OUT MSG,MSGLEN
;
COLFIN LD GR7,CHKSUM
ADDL GR4,GR7
ST GR4,CHKSUM
; DREG ='GR2 '
RPOP
RET
;
DATAMU DC 1 ; 1: *65536
DATAML DC 34464 ; 34464: 1*65536+34464=100000
DATAIU DC 0
DATAIM DC 0
DATAIL DC 0
CHKSUM DC 0
MSG DC 'ERROR'
MSGLEN DC 5
END
たかだか、いわゆる48ビット化(というほどでもないですが…)するのにとんでもなく冗長になってしまいました。具合が悪くなりそうですが、ベンチマークです。画面には表示できてませんが、100000と他と同じ数まで計算してます。
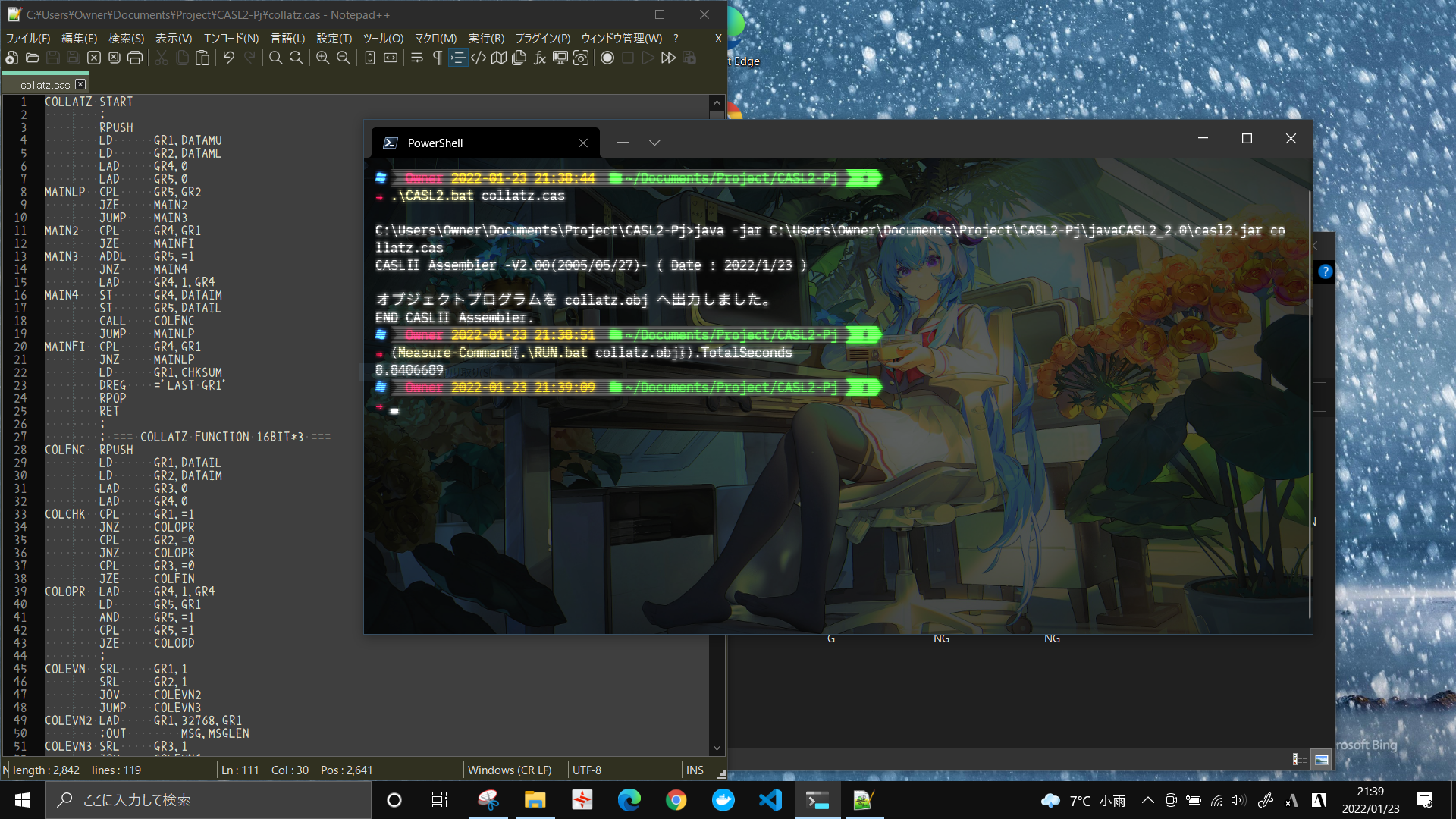
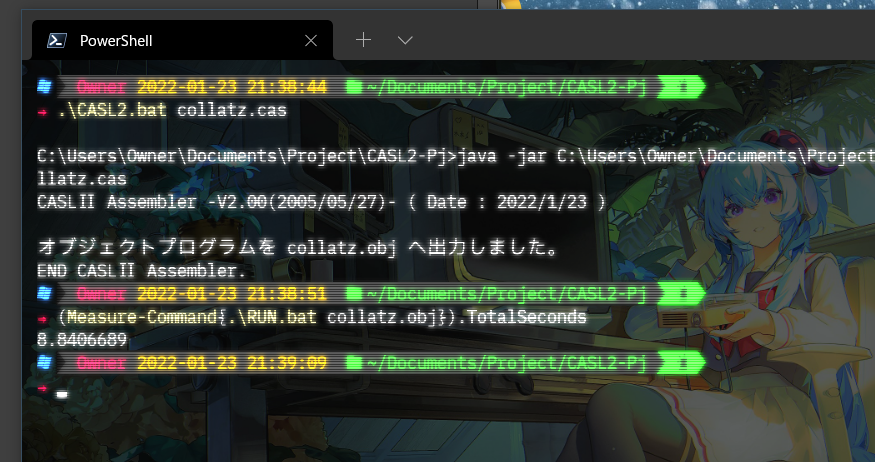
前回のCOBOLが7秒程度だったので、それと比較すると残念な気もしますが、案外そうでもなくて、JVMという仮想マシンの上の、さらにCOMMETさんという仮想マシンの上で動いている、デバッガ兼用の環境を考えると、とても優秀であるといえます。
👞C言語でも
シフト演算のメリットがわかりずらかったので、まずCの標準方法でシフト演算でやってみました。
#include <stdio.h>
#define ULONG_MAX 18446744073709551615UL
int collatz_len(unsigned long x) {
int n = 0;
while(x > 1) {
n++;
if (x & 1) {
x = (x << 1) + x;
x++;
} else {
x = x >> 1;
}
}
return n;
}
int main(void) {
// printf("%lu\n", ULONG_MAX);
unsigned long max;
printf("Collatz max: "); scanf("%lu", &max);
unsigned long i;
unsigned long sum = 0;
for (i=1; i<=max; i++) {
// int ans = collatz_len(i);
// printf("%d\n", ans);
sum += collatz_len(i);
}
printf("%lu\n", sum);
return 0;
}
64ビットが普通にロングで利用できるので、案外楽でした。ベンチです。
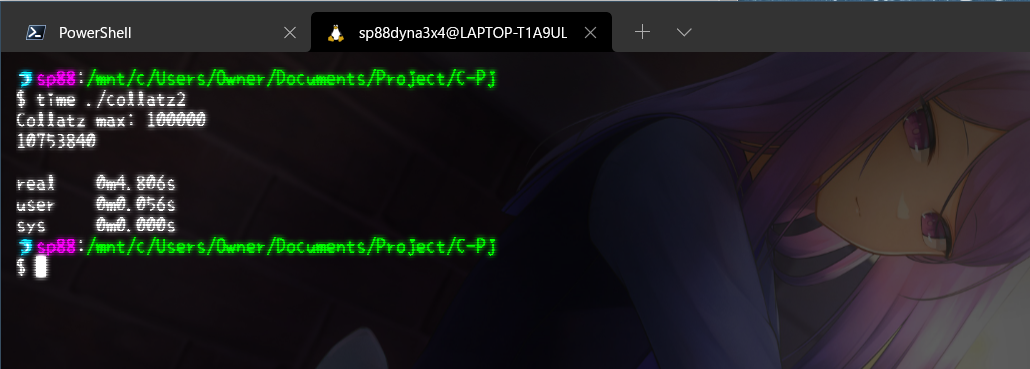
WSL2環境が重いのか、シフト演算のプログラム効果がないのか、そもそもCが速すぎるからなのかは分かりませんが、普通のプログラムの場合(約53ms)とたいして変わりませんでした。
前回参考にしたサイトに、同じ方法のCでのアセンブリ記述があったので、そちらでやってみました。
(参考)C言語:アセンブリ版
(結果)
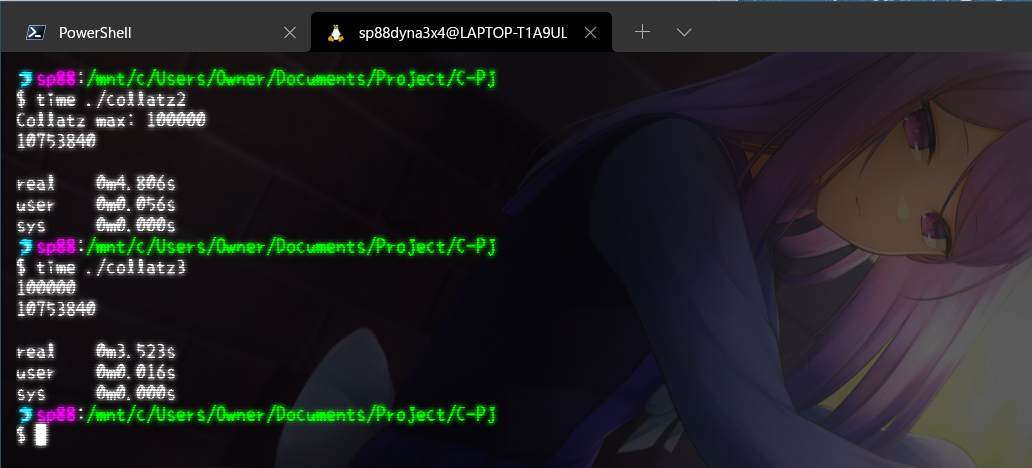
文句なしにぶっちぎりですね。ここから、情報技術者試験からCOBOLは無くなっても、CASL2:アセンブラは無くならないだろうことは、容易に想像できそうです。
☕~ おしまい ~☕
1人がサポートしています
7.00 ALIS













