822.04 ALIS
822.04 ALIS  139.19 ALIS
139.19 ALIS 

リンク:
アリスブログ > 「ALISのAPI」を使用する方法まとめ > 当記事
◆ 【Python】ALISのAPIのデータを「CSVファイル」に保存する方法
ついにやってきました! CSVファイルの保存の回!
CSVファイルを生成することができれば、表計算ソフト(エクセルとか)と連携を取ることができるようになるので、今まで集計していたデータの「保存や分析」が行えるようになります。とても重要です。
なので、しっかり覚えていきましょう!
○ 留意事項
・ファイルの作成を行ったら、最後に必ず、アプリを終了させて下さい。そうしないと、ファイルの情報が更新されないかもしれません
・本番用のプログラムは、実行速度が遅いです
○ 関連記事
◆ CSVファイルについて
CSV(comma-separated values)とは、項目を「,」(カンマ、コンマ)で区切った、テキストファイルのことです。
CSVデータの例:
a1,a2,ほげほげ,a4,
a5,a6,a7
上記のデータ列を、表計算ソフトで読み込んだ場合:

上記の「CSVデータの例」をメモ帳とかに保存して、「拡張子をcsv(中身は実質txt)」にすれば出来上がります。簡単です。
○ Pythonで「CSVファイル」を生成する方法
import codecs
str1 = 'a1,a2,ほげほげ,a4\na5,a6,a7'
file_name1 = 'csv1.csv'
file1 = codecs.open(file_name1,'w','utf-8')
file1.write(str1)
file1.close
input('Enterキーで終了')
テキストデータを保存するプログラムと、殆ど同じコードです。
・「\n」について
「\n」は改行の宣言です。これを入れておかないと、次の行に改行されないので、気をつけておいて下さい
「CSVファイル」を生成したい場合は、APIから出力されたデータを「A,B,C,D,E,F……」のように「,」で分けながら、文字列に保存しておけば良いというわけですね。
……それでは、次に、「本番での使用方法」を見ていきましょう!
◆ 記事の情報をCSVファイルに保存するプログラム
import urllib.request
import json
import pprint
import time
import math
import datetime
import codecs
#任意の値
user_name1 = 'yuuki'
load_num = 3 # 記事の呼び出しを行う数
#固定の値
article_id_memo1 = ''
sort_key_memo1 = ''
article_box2 = []
# 呼び出しする数の生成
if load_num < 1 : load_num = 1
limit1 = load_num
loop_num = (int)(1 + (load_num - 1) / 100)
if limit1 > 100 : limit1 = 100
for count1 in range(loop_num):
try:
url_name1 = f'https://alis.to/api/users/{user_name1}/articles/public?limit={limit1}'
if count1 >= 1:
url_name1 += f'&article_id={article_id_memo1}&sort_key={sort_key_memo1}'
cm_data1 = urllib.request.urlopen(url_name1)
article_box1 = json.loads(cm_data1.read().decode("utf-8"))
article_box2.extend(article_box1['Items'])
load_article1_len1 = len(article_box1['Items'])
print("Load : " + str(count1))
if load_article1_len1 <= 0:
break
else:
article_id_memo1 = article_box1['Items'][load_article1_len1 - 1]['article_id']
sort_key_memo1 = article_box1['Items'][load_article1_len1 - 1]['sort_key']
#time.sleep(1)
except:
print("Error!")
break
print("")
page2 = 0
load_article1_len2 = len(article_box2)
csv_str1 = '作成日時,タイトル名,いいねの数,ALISトークン\n'
csv_str_box1 = []
for article3 in article_box2:
title_name1 = article3['title']
date_str1 = (str)(datetime.datetime.fromtimestamp((int)(article3['sort_key'] / 1000000)))
url_name2 = f'https://alis.to/api/articles/' + article3['article_id'] + '/likes'
cm_data2 = urllib.request.urlopen(url_name2)
like_dict1 = json.loads(cm_data2.read().decode("utf-8"))
like1 = like_dict1['count']
url_name3 = f'https://alis.to/api/articles/' + article3['article_id'] + '/alistoken'
cm_data3 = urllib.request.urlopen(url_name3)
alis_token_dict1 = json.loads(cm_data3.read().decode("utf-8"))
alis_token1 = alis_token_dict1['alis_token'] / 1000000000000000000
alis_token2 = math.floor(alis_token1 * 100) / 100
csv_str_box1.append(f'{date_str1},{title_name1},{like1},{alis_token2}\n')
page2 += 1
print(f'Load ({page2} / {load_article1_len2}) : {title_name1} いいね : {like1} ALIS : {alis_token2}')
time.sleep(1)
for str1 in reversed(csv_str_box1):
csv_str1 += str1
file_name1 = user_name1 + '_ALIS_ArticleData.csv'
file1 = codecs.open(file_name1,'w','utf-8')
file1.write(csv_str1)
file1.close
print('')
print(f'CSVファイル「{file_name1}」を作成しました!')
print('')
print('要素数 : ' + str(len(article_box2)))
print('')
input('Enterキーで終了')
※1 説明しておきたい部分を太字にしています
※2 このソースコードは、「ALISユーザーの『いいねの数』と『獲得したALISトークン』を表示する方法」と「ALISの記事をバックアップする方法」に書かれているコードを合成したものです
○ 説明!
csv_str1 = '作成日時,タイトル名,いいねの数,ALISトークン\n'
CSVファイルの「冒頭の内容」を上記のようにしておきます。
csv_str_box1 = []
リスト型の宣言。
必要な文字列を、全て「csv_str1」に連結してしまっても良いのですが、
今回は「古い順から記事を表示したいため」、一度「リスト型」に「文字列」を格納して、順番の変更ができる状態にしておきます。
date_str1 = (str)(datetime.datetime.fromtimestamp((int)(article3['sort_key'] / 1000000)))
日付を文字列で保存しておくプログラムです。
記事の情報には、「['sort_key']」と呼ばれる「unix時間」を保存したものがあるので、そちらを利用した上で「fromtimestamp」を用いて、「unix時間」を日付のデータに変換しています。
・「 / 1000000」について
「['sort_key']」は精度が良すぎるので、秒単位以下のデータは捨てています。
・余談:「['published_at']」について
ALISの記事の情報には、「['published_at']」という名前の秒単位まで保存された「unix時間」のデータがあります。
こちらのほうが、「unix時間」を扱いやすいので、「['sort_key']」ではなく、「['published_at']」を使いたくなるものなのですが……、
なんと! (現時点での)この要素は「2018/05/01」、以前の「ALISの記事の情報」には含まれていないのです!
このことから、「['published_at']」で投稿時間を保存していると、記事を取得している最後の方で(大分待った後に)、プログラムがエラーになって強制終了を起こします。
鬼畜仕様です。ご注意下さい。
_(:3 」∠ )_ < このバグの発見に苦労したよ……
csv_str_box1.append(f'{date_str1},{title_name1},{like1},{alis_token2}\n')
CSVに保存しておきたいデータ(「日付,タイトル名,いいね数,ALISトークン数」)を、「csv_str_box1」に入れていきます。
for str1 in reversed(csv_str_box1):
csv_str1 += str1
「reversed」は、呼び出す配列を反転させるコードです。
これにを使って、CSVに保存しておきたいデータを「csv_str1」内に逆から入れていきます。
file_name1 = user_name1 + '_ALIS_ArticleData.csv'
file1 = codecs.open(file_name1,'w','utf-8')
file1.write(csv_str1)
file1.close
最初の方で説明した「Pythonで『CSVファイル』を生成する方法」をちょっとだけ改造したものです。
このプログラムで、任意の文字列を、CSVファイルに保存します。
○ 実行結果
・プログラムの確認
「user_name1 = 'yuuki'」「load_num = 10000」で起動
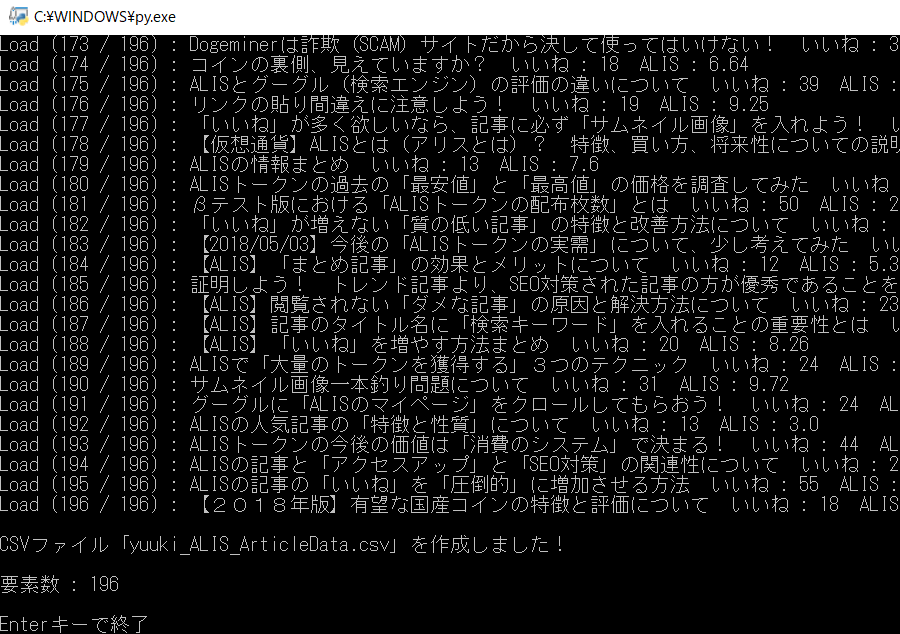
・生成されたCSVファイルの確認
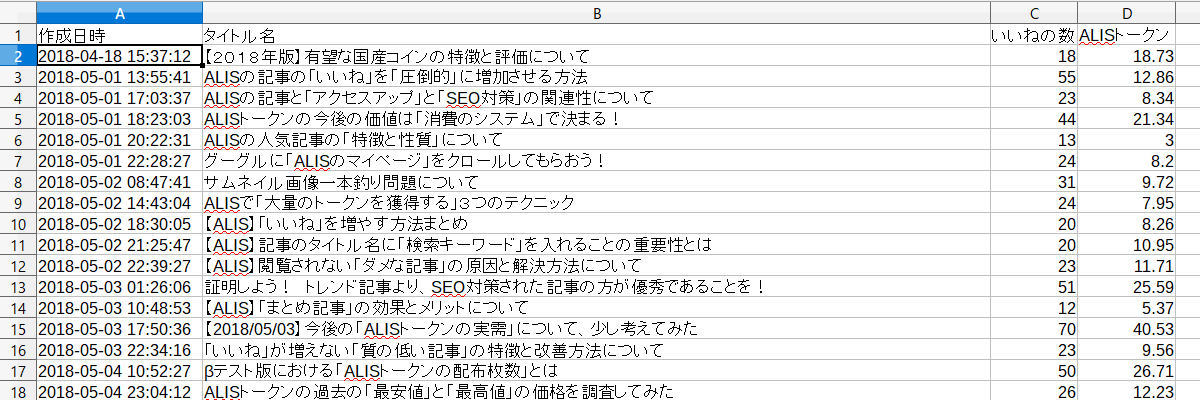
今回は、古い順から記事を並べています。
・私の記事の「いいね数」と「ALISトークン」の関係
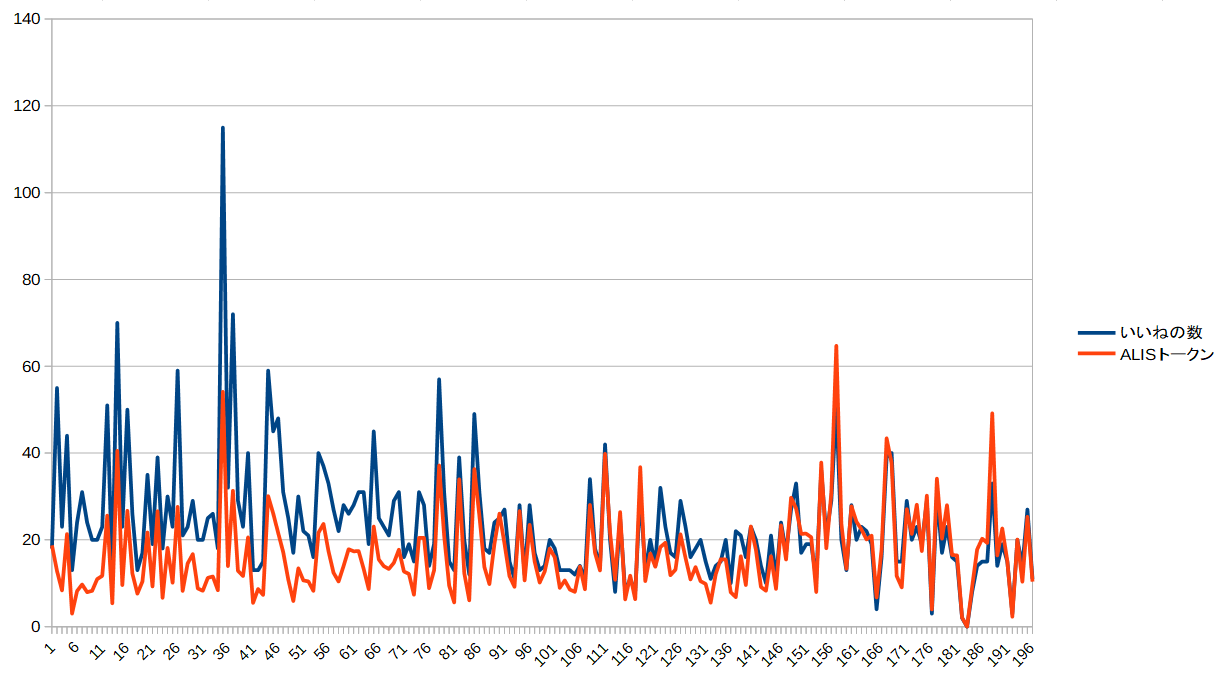
「APIの利用方法」と「CSVの操作」を覚えれば、
「ののたさん」が行っているような「ALISの分析データ」を出力することもできるようになります。
◆ 「ゆうき」のツイッター