822.04 ALIS
822.04 ALIS  139.19 ALIS
139.19 ALIS 

リンク:
アリスブログ > 「ALISのAPI」を使用する方法まとめ > 当記事
◆ 【Python】ALISの記事をバックアップする方法
「ALISの記事のバックアップファイルを生成する方法がない!」ということが、前々から気になっていたのですよね。
……ということで、自力で作ってみました。
下記のプログラムを用いれば、自分の記事のバックアップを作成することができますよ。
○ 留意事項
・「2018/09/13」に作成された記事です
・ALISのAPIの仕様が変わると、このプログラムは動作しなくなる可能性があります
・バックアップ用のプログラムは、ALISサーバーに「負荷がかかりやすい」です
・バックアップ用のプログラムは実行速度が遅いです
・バックアップ用のプログラムを同じ日付内で実行すると、バックアップしたファイルが「上書き」されます
・当プログラムでバックアップを行うのは「テキストデータのみ」です。画像ファイルを保存することはできません
○ 関連記事
◆ バックアップ用のプログラム
○ 記事のバックアップを生成するプログラム
import urllib.request
import json
import pprint
import time
import datetime
import ast
import codecs
# 任意の値
user_name1 = 'yuuki'
load_num = 3 # 記事の呼び出しを行う数
# 固定の値
article_id_memo1 = ''
sort_key_memo1 = ''
article_box2 = []
# 呼び出しする数の生成
if load_num < 1 : load_num = 1
limit1 = load_num
loop_num = (int)(1 + (load_num - 1) / 100)
if limit1 > 100 : limit1 = 100
for count1 in range(loop_num):
try:
url_name1 = f'https://alis.to/api/users/{user_name1}/articles/public?limit={limit1}'
if count1 >= 1:
url_name1 += f'&article_id={article_id_memo1}&sort_key={sort_key_memo1}'
cm_data1 = urllib.request.urlopen(url_name1)
article_box1 = json.loads(cm_data1.read().decode("utf-8"))
article_box2.extend(article_box1['Items'])
load_article1_len1 = len(article_box1['Items'])
print("Load : " + str(count1))
if load_article1_len1 <= 0:
break
else:
article_id_memo1 = article_box1['Items'][load_article1_len1 - 1]['article_id']
sort_key_memo1 = article_box1['Items'][load_article1_len1 - 1]['sort_key']
#time.sleep(1)
except:
print("Error!")
break
print("")
page2 = 0
load_article1_len2 = len(article_box2)
article_box5 = []
for article3 in article_box2:
article_id1 = article3['article_id']
url_name2 = f'https://alis.to/api/articles/{article_id1}'
cm_data2 = urllib.request.urlopen(url_name2)
article_box4 = json.loads(cm_data2.read().decode("utf-8"))
article_box5.append(article_box4)
time.sleep(1)
page2 += 1
print(f"Copy ({page2} / {load_article1_len2}) : " + article3['title'])
if load_article1_len2 >= 1 :
text1 = json.dumps(article_box5,ensure_ascii = False)
date1 = datetime.date.today()
file_name1 = str(date1) + '_' + user_name1 + '_ALIS_BackupData.txt'
file1 = codecs.open(file_name1,'w','utf-8')
file1.write(text1)
file1.close
print("")
print(f"保存数 : {page2}")
print(f"バックアップファイル「{file_name1}」を作成しました!")
print("")
else:
print(f"保存するデータがありませんでした……")
input('Enterキーで終了')
※1 このソースコードは「特定のALISユーザーの『記事の情報』を全部取得してみよう!」に掲載されているコードを改造したものです
※2 説明しておきたい場所は、太字にしています
○ 作成したバックアップデータを読み込むプログラム
import pprint
import datetime
import ast
import codecs
# 任意の値
user_name1 = 'yuuki'
date2 = '2018-09-13' # 任意の日付
file_name2 = str(date2) + '_' + user_name1 + '_ALIS_BackupData.txt'
file2 = codecs.open(file_name2,'r','utf-8')
file_str1 = file2.read()
article_box6 = ast.literal_eval(file_str1)
file2.close
for article7 in article_box6:
print(article7['title'])
print("")
print("要素数 : " + str(len(article_box6)))
print("")
input('Enterキーで終了')
※ こちらのソースコードの説明は省きます
○ 説明!
import codecs
今回のコードでは、「指定した文字コードでのファイルの保存」が必要となるため、「codecs」のモジュールを入れておきます。
load_num = 3 # 記事の呼び出しを行う数
前回まで「limit1」「loop_num」を設定していましたが、今回から変数1つで「呼び出し数」を決められるようにします。
# 呼び出しする数の生成
if load_num < 1 : load_num = 1
limit1 = load_num
loop_num = (int)(1 + (load_num - 1) / 100)
if limit1 > 100 : limit1 = 100
変数1つで「呼び出し数」を決められるようにした結果、必要なコードが増えてしまいました……(汗)。
article_id1 = article3['article_id']
url_name2 = f'https://alis.to/api/articles/{article_id1}'
2回目のループ文では、1回目のループ文で獲得した「各記事の番号」を使って「/articles/{article_id}」のAPIを呼び出します。
これを行うことで、記事内(body内)のHTMLデータを取得することができるようになります。
(バックアップを行う上で必要になるデータです)
article_box5.append(article_box4)
「extend」を用いると、(型落ちで)保存されていたデータが消えてしまうので、「append」に変更しました。
・「append」と「extend」の使い分けについて
サンプルプログラムを組んでみると、わかりやすいです。
list1 = {"A":1, "B":2, "C":3}
list2 = {"Items": [{"A":1, "B":2, "C":3}]}
list4 = []
list5 = []
list6 = []
list7 = []
for test1 in range(2):
list4.append(list1)
list5.extend(list1)
list6.append(list2['Items'])
list7.extend(list2['Items'])
print(list4)
print(list5)
print()
print(list6)
print(list7)
input('Enterキーで終了')
・サンプルの出力結果
[{'A': 1, 'B': 2, 'C': 3}, {'A': 1, 'B': 2, 'C': 3}]
['A', 'B', 'C', 'A', 'B', 'C']
[[{'A': 1, 'B': 2, 'C': 3}], [{'A': 1, 'B': 2, 'C': 3}]]
[{'A': 1, 'B': 2, 'C': 3}, {'A': 1, 'B': 2, 'C': 3}]
外に要素(「['Items']」)が無い時は「append」。
外に要素がある時は「extend」を用いることで、[]内に「{}のみ」を複数配置することができます。
(「append」は全部そのまま追加、「extend」は中身を追加。という認識でいいような気がします)
page2 += 1
print(f"Copy ({page2} / {load_article1_len2}) : " + article3['title'])
「リクエストした記事の数」を確認できるようにしてみました。
text1 = json.dumps(article_box5,ensure_ascii = False)
リスト型のデータを「unicode文字無し」の文字列で出力するプログラムです。
これを使うと、「text1 」の内部にある辞書型のデータを、日本語の状態で文字列に入れることができます。
(通常の「json.dumps()」の場合は、日本語が「\u3042」のような形式で保存されます)
date1 = datetime.date.today()
「年-月-日」を取得します。
file_name1 = str(date1) + '_' + user_name1 + '_ALIS_BackupData.txt'
保存するファイル名の設定です。
この記事を作成した日付(2018/09/13)で、私の記事(yuuki)をバックアップした場合は、「2018-09-13_yuuki_ALIS_BackupData.txt」というファイル名になります。
file1 = codecs.open(file_name1,'w','utf-8')
「file_name1」のファイルを書き込み専用でロードした後(ファイルが存在しない場合は、新規で作成した後)「utf-8」形式で書き込めるようにします。
(「json.dumps」で「ensure_ascii = False」を宣言した場合は、「codecs」を使用しておかないと、記事内で稀にある「変な文字(?)」を書き込んだ際にエラーが発生します)
file1.write(text1)
変数に保存しておいた「ALISの記事のデータ」を、読み込んだファイルに書き込みます。
file1.close
やるべきことを終えたら、「close」でファイルを閉じます。
○ 実行結果
・バックアップデータをセーブするプログラム
「user_name1 = 'yuuki'」「load_num = 10000」で実行。
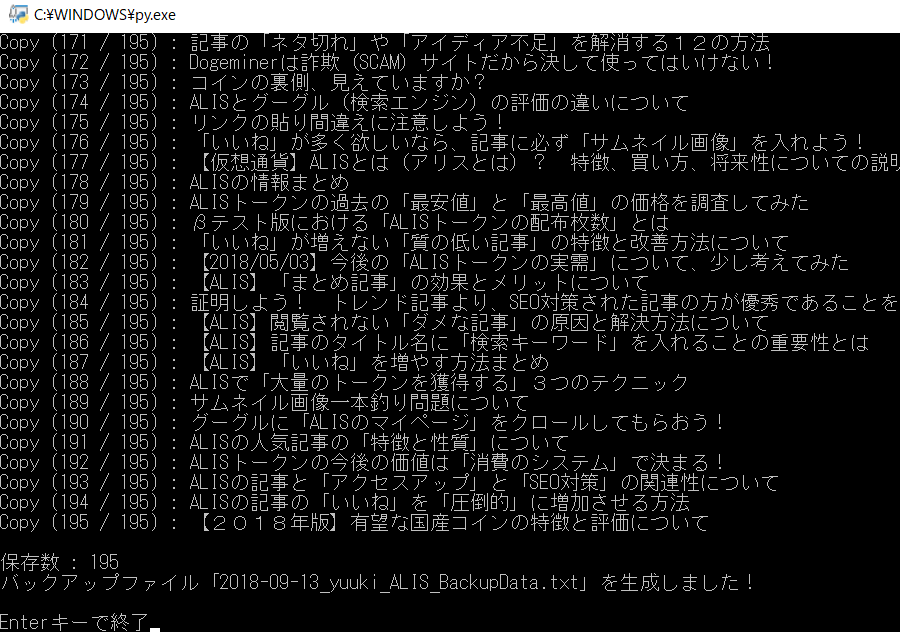
「195記事」保存したら、テキストの容量が「1.5MB」になっていました。
・バックアップデータの中身
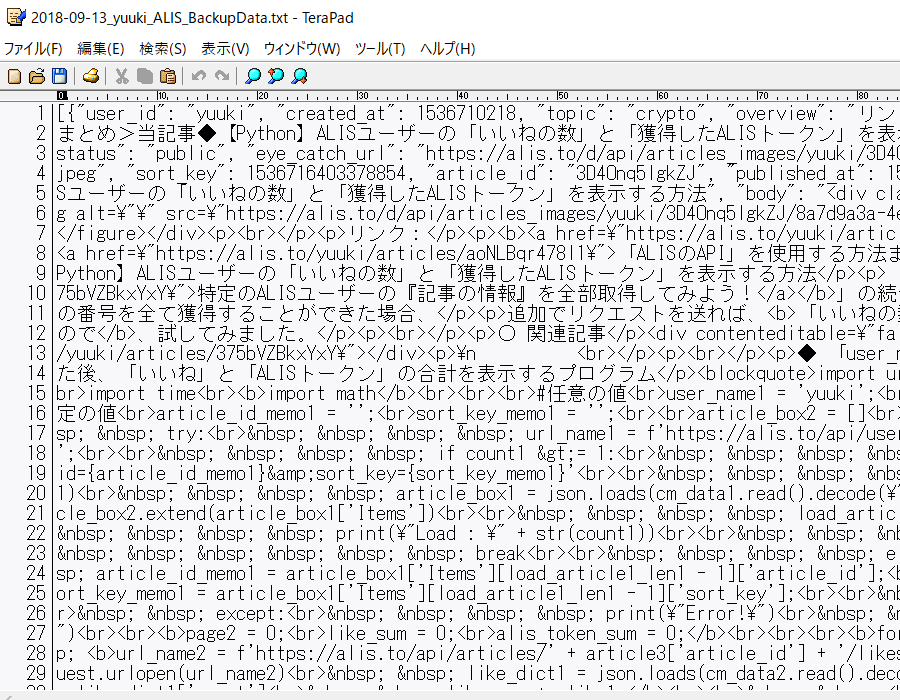
「JSONデータ」と「(日本語が含まれた)HTMLデータ」の確認を行うことができます。
・バックアップデータをロードするプログラム
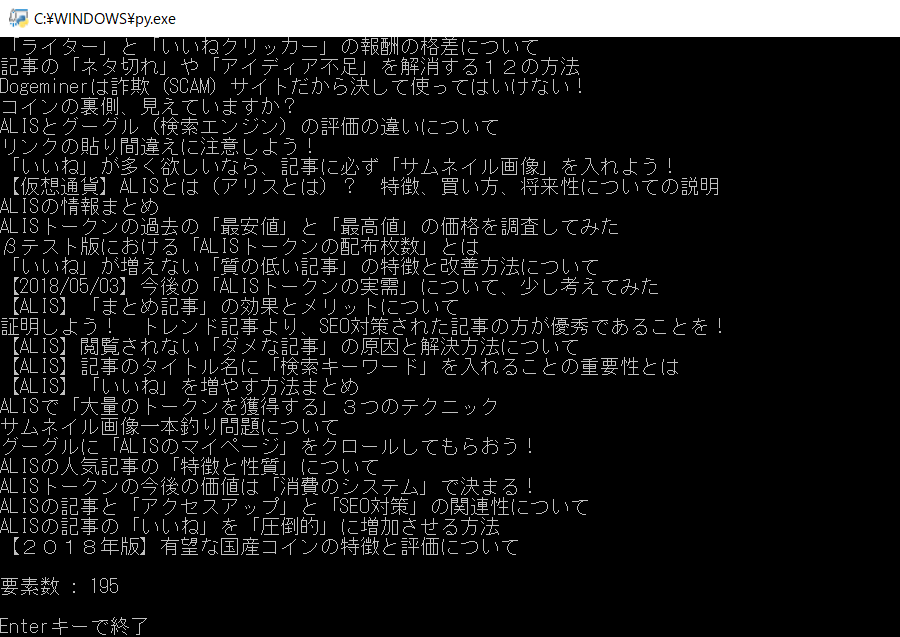
ロードは行えるようにしましたが、元の記事データに戻す機能は入れていないので、もし復元が必要になったら、ハッカー部とかに「出力プログラム」の制作を依頼して下さい(丸投げ)。
・余談
「user_name1」の値を「他のALISユーザーのID」に変更すれば、その人の全記事をバックアップすることもできます。
◆ 「ゆうき」のツイッター